
Smart Engineering : Airflow ? Ça brasse du vent ?
Introduction
Non, Airflow ne brasse pas le vent mais plutôt des données !
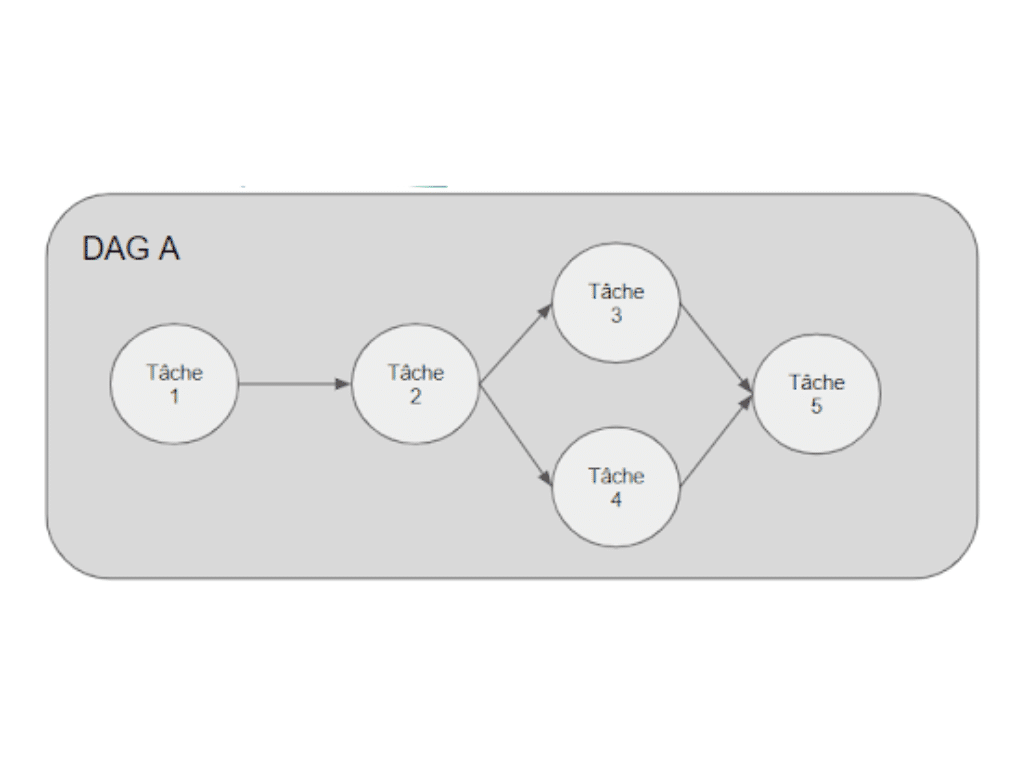
Airflow est une plateforme servant à écrire, planifier et monitorer des flux de données programmatiquement.
Ils sont représentés sous la forme de DAGs (Directed Acyclic Graph).
Airflow a été créé par AirBnB en 2015 par Maxime Beauchemin. Le projet OpenSource a déjà fait l’objet de plus de 13 000 forks et affiche plus de 35 000 stars. Près de 2900 contributeurs font évoluer le produit le rendant utilisable par un nombre important d’entreprises en OSS sous Licence Apache.
Airflow est également disponible en Saas via la société Astronomer ou encore en PaaS sur les plateformes Google Composer et Amazon MWAA.
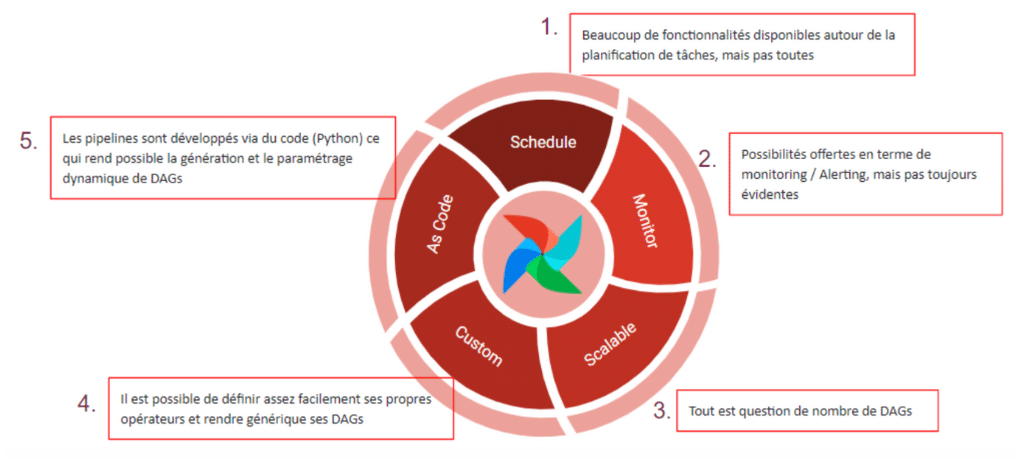
Ses principaux concurrents
Pourquoi l’utiliser ?
Airflow est très souvent utilisé pour opérer des workloads très gourmands en temps de traitement tels que les entrainement de modèles de machine learning.
Ce produit convient très bien au séquencement des traitements de données en permettant de chaîner les tâches entre elles au sein de workflows que vous pourrez ensuite planifier ou déclencher sur évènement.
Enfin il peut également jouer le rôle d’ELT principalement grâce à ses nombreux opérateurs.
Comment ça marche ?
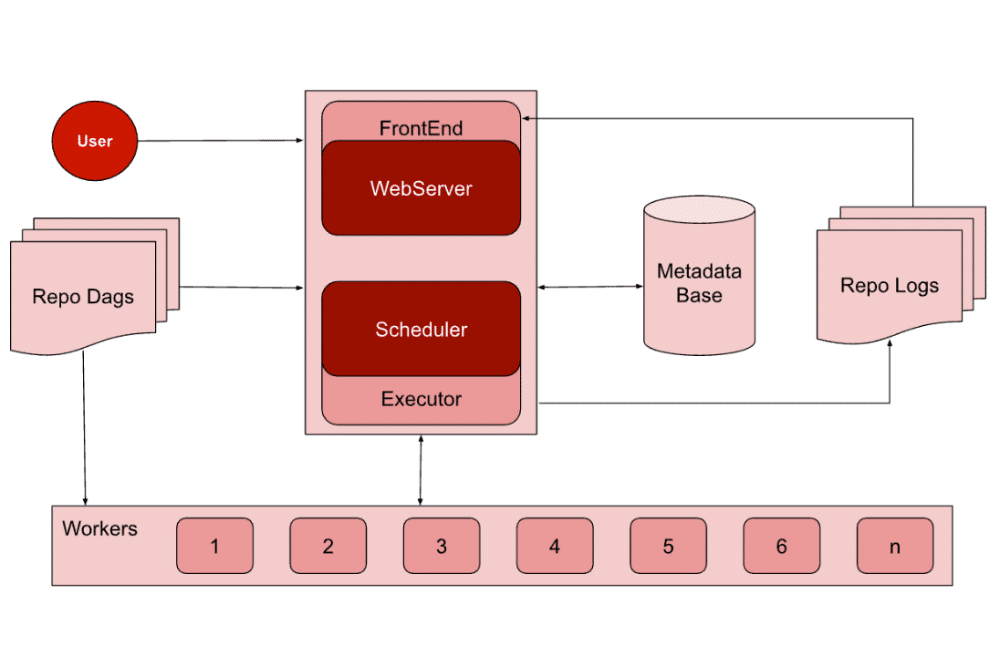
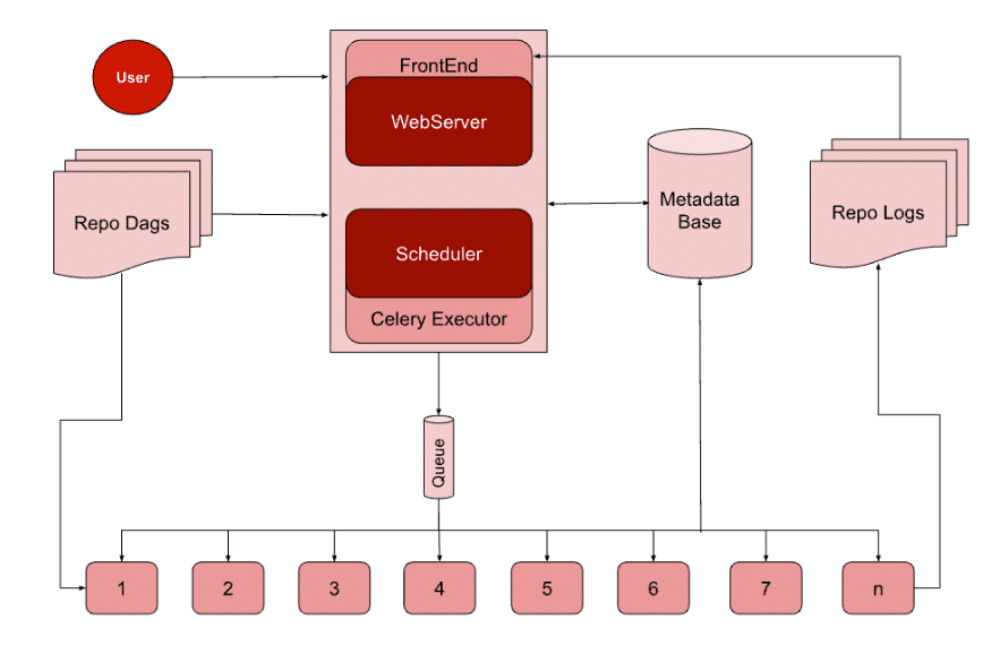
Afin d’appréhender au mieux l’architecture technique et fonctionnelle de l’outil, il est nécessaire de partager un peu de vocabulaire. Voici donc les principaux termes qui composent le paysage technique d’Airflow :
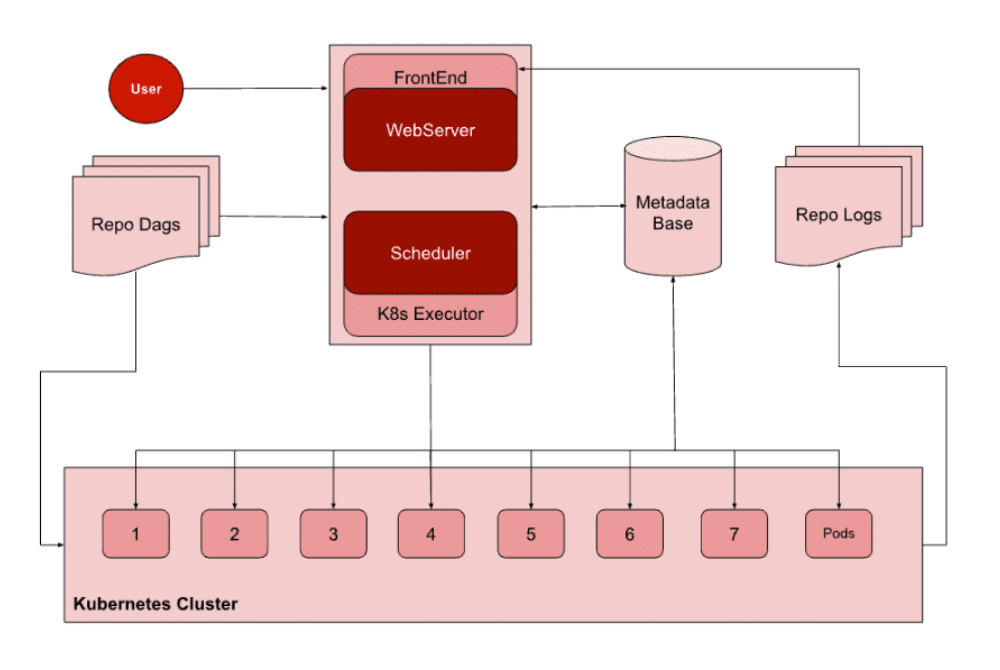
Scheduler
Il est chargé de déclencher les DAG ainsi que les tâches en fonction de leur calendrier et de leurs dépendances. Pour ce faire, il surveille les tâches et lance les tâches dépendantes en aval une fois que les tâches en amont sont terminées. C’est ainsi qu’il soumet les tâches à un executor.
Worker
Ce sont les machines où les tâches sont exécutées. Cela peut être sur la même machine/nœud où le planificateur s’exécute, si l’on utilise des exécuteurs à nœud unique ou une machine/nœud dédiée si l’on utilise des exécuteurs à nœuds multiples.
Metadata Base
C’est la base de données qui stocke les états des flux de travail, la durée d’exécution, les emplacements des journaux, etc. Cette base de données stocke également des informations concernant les utilisateurs, les rôles, les connexions, les variables, etc.
Repo Dags
C’est le Repository où Airflow stocke tout le code des DAG. Il est accessible au scheduler, au webserver et aux workers.
Executor
Un executor est la partie du scheduler qui traite et gère les tâches en cours d’exécution. Airflow fournit différents types d’executors, notamment les principaux :
– exécuteur local
– exécuteurs multi-nœuds : Celery Executor, Kubernetes Executor
WebServer
C’est ce service qui sert l’interface utilisateur permettant de visualiser, de contrôler et de surveiller tous les DAG. Cette interface permet de déclencher manuellement un DAG ou une tâche, d’effacer les exécutions du DAG, de visualiser les états et les journaux des tâches et de visualiser la durée d’exécution des tâches. Elle permet également de gérer les utilisateurs, les rôles et plusieurs autres configurations d’Airflow.
Repo logs
C’est le repository où Airflow stocke les logs de toutes les tâches terminées. L’adresse de chaque tâche exécutée est stockée dans la base de données des métadonnées. L’utilisateur peut alors visualiser les logs à partir de cet emplacement via l’interface utilisateur du webserver. Airflow peut également être configuré pour définir un répertoire de logs distant, par exemple s3 ou GCS.
Les différentes architectures
Maintenant que l’on sait de quoi nous parlons, arrêtons nous sur les différentes architectures que l’on peut mettre en place pour installer Airflow.
Architecture technique Executor mono noeud
Architecture technique Executor multi noeuds Celery
Architecture technique Executor multi noeuds Kubernetes
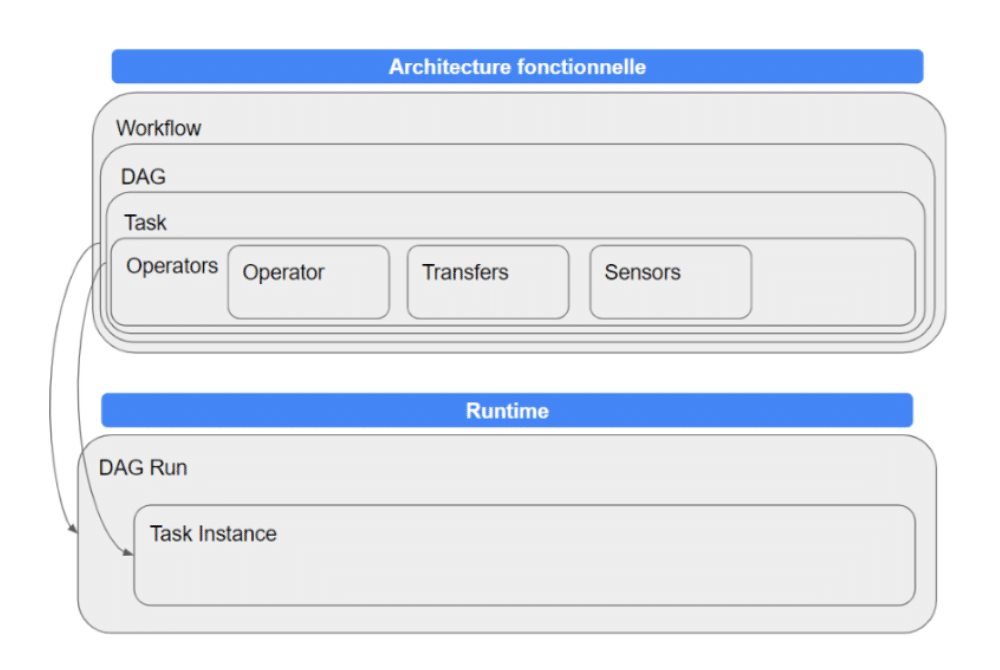
- Dag : Décrit la façon dont est orchestrée une série de tâches qui forme un flux.
- Dag Run : C’est une instance d’un DAG fonctionnant à un moment donné.
- Operator : Décrit une tâche à exécuter de façon atomique.
- operator : une action à effectuer (shell, call api, python)
- transfer : un spécifique pour transférer des données (bq to gcs operator)
- sensor : déclencheur sur event (fichier sur s3)
- Task : Représente un opérateur paramétrisé
- Task Instance : C’est une instance d’une tâche exécutée à un moment donné avec un paramétrage précis.
- X-Com : Canal d’échange d’informations entre tâches sous forme de Key-Value.
Échantillon des opérateurs disponibles

Avantages et inconvénients
Langage de programmation
L’un des avantages mais aussi des plus gros inconvénients de Airflow est son langage de programmation, Python.
En effet, cela permet de disposer de beaucoup de profils tech sur le marché et d’accroître la productivité. Il est également possible d’introduire des logiques de programmation telles que la création de Dags dynamique en fonction des besoins. Mais cela engendre aussi des problématiques de maintenance du produit de façon générale et entraîne souvent des soucis de dépendances.
Scalabilité
L’autre point ambivalent de la solution est sa scalabilité.
Depuis la version 2 du produit, tous les services sont scalables horizontalement, rendant le produit hautement disponible et normalement tolérant aux fautes. Cependant il est difficile de gérer efficacement cette scalabilité sans exploser les coûts au niveau de la consommation des ressources de Compute.
Communauté
La communauté qui s’active autour du produit est un atout également, ne laissant jamais ses utilisateurs sans réponse aux nombreuses questions qu’ils peuvent se poser au détour de la learning curve assez importante qu’ils doivent acquitter pour être opérationnels sur des projets de production à l’échelle.
Le nombre d’opérateurs disponibles contribue également aux avantages du produit.
Développement
En revanche, l’impossibilité de développer directement depuis le frontend de la solution peut devenir assez rédhibitoire en fonction de la cible utilisateur que vous devez adresser, de même que l’absence de gestion d’un quelconque versionning des Dags sans un bon Source Code Manager en back.
Sécurité
Enfin, dès lors que l’on souhaite mutualiser une instance de Airflow sur plusieurs périmètres fonctionnels avec des utilisateurs en provenance de domaines différents, il devient très compliqué de sécuriser les opérations et les accès aux ressources.
Retex de nos interventions Clients Grands Comptes
Deux de nos clients ayant tenté l’aventure du traitement de données à l’échelle mondiale avec Airflow en mode Event Driven se sont frottés à différents problèmes
- Complexité des tâches simples : La création de workflows sans standardisation est une tâche fastidieuse.Cela peut créer beaucoup de bruit et ralentir les projets.
- Problèmes de fiabilité : Airflow s’est avéré peu fiable, les tâches échouant souvent à cause de l’orchestrateur lui-même plutôt que d’erreurs dans le code. Ces problèmes de fiabilité peuvent faire perdre beaucoup de temps, réduisant ainsi la productivité globale.
- Sécurité : La gestion des RBAC ainsi que des utilisateurs n’aide pas à sécuriser la plateforme de façon globale, rendant son utilisation difficilement mutualisable dans un contexte multi pays, multi projets, multi utilisateurs.
- Longs délais de traitement : Dans certains cas, la durée des flux de données orchestrés par Airflow était vingt fois plus longue qu’avec d’autres outils de flux. Airflow nécessite une quantité importante de ressources CPU et de mémoire pour gérer des charges de travail même modérées, ce qui entraîne une augmentation des coûts d’infrastructure et des goulots d’étranglement potentiels au niveau des performances.
En faisant en sorte de standardiser les développements au travers de la mise à disposition de Dags pré-développés ne nécessitant plus que du paramétrage, nous avons pu gommer une partie de ces irritants et en tirer quelques bénéfices :
- Homogénéisation des développements : onboarding plus rapide des nouveaux développeurs
- Respect des règles d’architecture
- Respect des règles de qualité de données
- Recentrage des développeurs sur le fonctionnel
- Amélioration du TimeToMarket
- Facilitation du Run
Cependant, cela ne nous a pas permis de contrebalancer totalement les pain points décrits plus haut, nous obligeant à trouver d’autres solutions.
Vous rencontrez les mêmes problématiques ? La meilleure alternative qui permet de traiter tous les points énoncés se trouve juste ici 👉 kestra.io