Détection de Doublons Retail : De l’Audit Power BI à l’Industrialisation GCP
![]()
![]()
Lorsqu’on aborde la qualité des données dans le retail, la question n’est jamais de savoir s’ il y a des doublons, mais combien ils coûtent réellement. C’est tout l’enjeu du diagnostic architectural : transformer une impression diffuse (« on a des soucis de qualité ») en une métrique actionnable. C’est précisément le défi relevé pour l’un de nos clients grands comptes, enseigne bien connue du retail, dont le référentiel de 1,6 million de clients hébergé sur Google Cloud Platform (GCP) nécessitait un audit en profondeur.
L’analyse a révélé près de 110 000 comptes actifs en doublon (soit un taux de friction de 1,61%). Au-delà du simple stockage, ce chiffre se traduit par une perte sèche annuelle estimée à 5 000 € rien que sur le canal emailing, sans compter la vision client fragmentée qui rend inopérant tout effort de personnalisation marketing.
1. Le Diagnostic : Pourquoi le SQL ne suffit plus
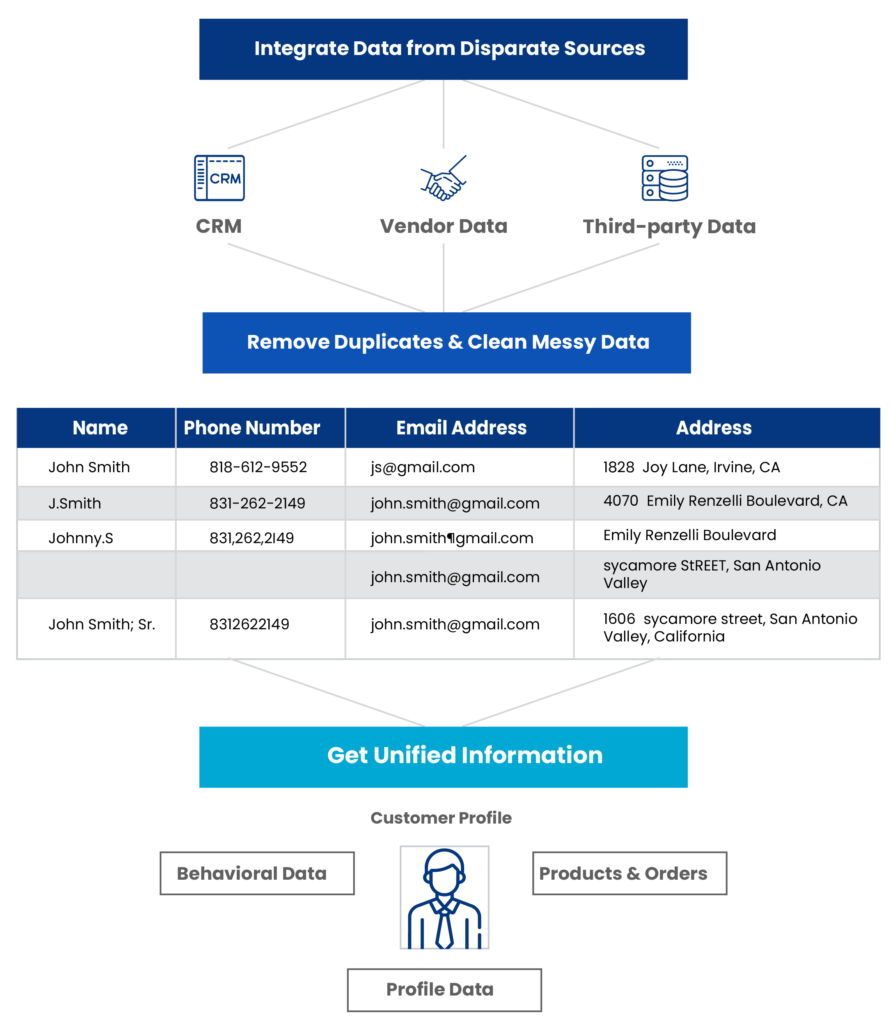
La première limite rencontrée dans ce type de projet est souvent méthodologique. L’approche traditionnelle par « matching exact » (SQL strict sur nom/prénom/email) échoue systématiquement face à la réalité humaine de la saisie en magasin ou en ligne.
L’audit des données client a mis en lumière les cas d’usage typiques qui passent sous les radars d’une requête classique :
- Variations phonétiques et fautes de frappe : Un « gmel.com » au lieu de « Gmail.com » est techniquement différent, mais représente la même intention.
- Formats hétérogènes : Le classique préfixe international (+33 vs 06) qui casse les clés de jointure.
- Évolutions d’identité : Les changements de noms (mariage, usage) qui créent des identités parallèles.
Face à ces contraintes, l’utilisation d’un algorithme de matching probabiliste (fuzzy logic), capable d’attribuer un score de confiance plutôt qu’un résultat binaire, s’est imposée comme une nécessité technique.
2. Architecture Hybride : Le tandem Power BI & Python

Pour prototyper rapidement cette logique sans lancer un chantier d’infrastructure lourd, le choix s’est porté sur une architecture hybride : utiliser Power BI non pas seulement comme outil de visualisation, mais comme orchestrateur léger d’un script Python.
La mécanique d’intégration
- Le principe repose sur l’injection de la puissance de transformation de Python au sein du pipeline Power Query. Concrètement, Power Query assure le nettoyage préliminaire (ETL) et passe la main à un script Python via un DataFrame pandas.
Ce choix architectural nécessite quelques prérequis sur le poste de développement :
- Un environnement Python standard.
- Les bibliothèques pandas et numpy (socle de manipulation des DataFrames).
- Une gestion fine des droits d’exécution locaux.
Le pipeline technique s’est d’ailleurs appuyé sur l’IA générative pour initier les premières versions de l’algorithme de matching, ensuite raffinées par itérations successives pour s’adapter aux spécificités du dataset du client.
Le piège du casting silencieux
Un point de vigilance est apparu lors de l’intégration : la conversion des types de données entre le moteur Power BI et Python. Le cas des numéros de téléphone est le plus significatif.
Lors du passage du dataset vers Python, Power BI a tendance à interpréter les colonnes numériques, même si elles sont des identifiants (comme un numéro de téléphone). Résultat : les chaînes « 0612… » sont castées en entiers « 612… », perdant le zéro non significatif. Cette altération rend le matching impossible.
La « ruse » technique contournant ce comportement consiste à préfixer artificiellement les champs sensibles (par exemple avec un « + ») dans Power Query pour forcer le typage texte, puis à nettoyer ce préfixe une fois les données chargées dans le script Python.
3. Gouvernance : La donnée client n’est pas une donnée comme les autres
Traiter des données PII (Personally Identifiable Information) impose une rigueur absolue. L’audit a mis en exergue que la technologie ne peut pas tout résoudre si la gouvernance des données en amont est défaillante.
Le profiling des données a révélé des pratiques métier génératrices de dette technique :
- Saisies « bouchon » : L’usage de numéros fictifs (+00, 123456) pour contourner les champs obligatoires en caisse.
- Interfaces permissives : Des formulaires web ou caisse créant des doublons par défaut, faute de contrôle d’existence préalable.
Il semble pertinent d’instaurer des standards de normalisation stricts en amont de tout traitement algorithmique : formatage E.164 pour les téléphones (+33), validation des domaines MX pour les emails, et nettoyage des caractères spéciaux. C’est ce travail de fond sur la standardisation qui garantit la pertinence du score de confiance final.
4. Stratégie d’Industrialisation : Du Labo à l’Usine
Si l’architecture Power BI + Python est idéale pour l’audit et le prototypage (le « Lab »), elle montre vite ses limites en production. Pour traiter les 1,6 million d’enregistrements du client, le refresh Power BI nécessitait entre 5 et 6 heures. Ce temps de traitement s’explique par l’overhead mémoire massif généré par le transfert des données entre le moteur M de Power BI et l’environnement Python.
L’architecture cible sur GCP
Pour passer à l’échelle, l’architecture a dû être découplée :
- Traitement (Compute) : Le script Python, validé en phase POC, est porté en script standalone sur Google Cloud Platform. Exécuté en batch, il traite la volumétrie en quelques minutes.
- Stockage : Les résultats (paires de doublons et scores) sont persistés dans une table dédiée (BigQuery ou SQL).
- Visualisation : L’outil BI (ici Qlik, selon la stack client) se connecte en lecture seule sur cette table pré-calculée.
Cette approche de pipeline permet de séparer le cycle de vie du calcul (lourd, périodique) de celui de la restitution (rapide, à la demande).
5. ROI et Vision Long Terme
L’opération a permis de quantifier le ROI immédiat : réduction des coûts de stockage, économies sur les campagnes marketing (email/SMS), et surtout, une base saine pour réactiver le ciblage client.
Cependant, le nettoyage de données n’est pas une action ponctuelle. La recommandation stratégique porte sur la mise en place de cycles itératifs :
- Monitoring : Surveiller l’apparition de nouveaux doublons post-nettoyage.
- Root Cause Analysis : Remonter à la source (interfaces, formation des vendeurs) pour tarir le flux de création de doublons.
- Scalabilité : Adopter des architectures cloud-natives capables d’absorber la croissance organique des bases retail.
L’expertise Data de NTICO
Chez NTICO, nous abordons ces projets avec une double casquette : technique et métier. Notre expérience sur la mise en place de Data Platforms d’envergure nous permet de naviguer de l’audit initial jusqu’à l’industrialisation complexe.
Nous ne nous contentons pas de fournir un script ; nous construisons l’architecture de données qui soutient votre croissance. Que ce soit sur des problématiques de gouvernance, d’orchestration DataOps ou d’architectures hybrides, nos équipes transforment vos contraintes de qualité de données en leviers de performance opérationnelle.