L'interopérabilité des données
Introduction
Les données sont devenues un élément essentiel pour la prise de décision des entreprises. La multiplication des sources et des formats de données dans un SI en constante évolution crée un défi majeur : l’interopérabilité.
Le potentiel de partage et de réutilisation des données de l’entreprise dépend de leur qualité, de leur découvrabilité et de leur gestion globale.
Afin de pouvoir pleinement dégager ce potentiel, chaque entreprise doit développer l’interopérabilité de ses données selon plusieurs axes que nous allons détailler.
Pourquoi a-t-on besoin de gérer l’interopérabilité des données ?
L’interopérabilité des données est la capacité de différents systèmes et applications à échanger et à utiliser des données de manière efficace, tant dans un contexte opérationnel que analytique.
Amélioration des prises de décision
Améliorer la prise de décision grâce aux données est devenu un enjeu fort pour les entreprises et accéder à une vue complète des données qu’ils ont à disposition doit leur permettre de prendre des décisions plus éclairées et plus rapides, en réduisant les silos d’information.
Stimulation de l'innovation
Cela aura également pour effet de stimuler l’innovation en permettant aux différents acteurs de l’entreprise d’accéder à de nouvelles sources de données et ainsi de développer de nouveaux produits et services.
Optimisation de l'intégration des données
Il est tout aussi important de diminuer les efforts de transformation et d’intégration des données pour gagner en qualité de données et en homogénéité du code source tout en facilitant l’automatisation des processus.
Collaboration et productivité
Enfin, améliorer la collaboration et la productivité des équipes en réduisant le cold start permettra de réduire le time to market mais aussi de réaliser des économies importantes sur le build des solutions.
Formes d’interopérabilité des données
Les formes d’interopérabilité des données sont multiples, chacune répondant à des besoins spécifiques.
Technique
Nous allons parler d’interopérabilité technique dès lors qu’il est question de la capacité des systèmes à échanger des données via des formats et des protocoles standardisés.
Sémantique
Il s’agit d’interopérabilité sémantique lorsque l’objectif consiste à permettre à des systèmes, mais également des utilisateurs, de comprendre la signification des données échangées ou consommées grâce à l’utilisation d’un vocabulaire commun.
Organisationnelle
Enfin, la mise en place de processus et de règles communes qui permettent à l’entreprise de collaborer et de partager des données de manière transparente et efficace fait référence à l’interopérabilité organisationnelle.
Comment garantir l’interopérabilité des données ?
La mise en place de l’interopérabilité des données est un processus complexe qui nécessite une approche holistique. L’entreprise doit donc se saisir de chacun des sujets qui seront abordés ci-dessous dans leur globalité, dans un planning maîtrisé, traitant en priorité les points les plus lacunaires, leur permettant de gagner rapidement et/ou facilement en efficacité opérationnelle.
Gouvernance des données
Définition de politiques de gouvernance des données
Il est bien sûr évident que la première chose à faire pour l’entreprise sera de définir des politiques de gouvernance des données pour garantir la qualité, la sécurité et l’accessibilité des données.
En définissant des standards de qualité pour les données, comme par exemple la non publication d’un jeu de données affichant une qualité non contrôlée ou inférieure à un seuil défini, il sera possible de maîtriser en sortie la qualité des indicateurs affichés. La qualité d’une donnée se mesure au travers des caractéristiques qui lui sont propres, pour lesquelles il est possible de mesurer l’exactitude, l’exhaustivité, la cohérence, la validité, la fraîcheur, l’intégrité ou encore la clarté. Il faudra pour cela mettre en place des processus pour garantir que les données sont conformes à ces standards, comme des moteurs de scoring ou encore des dashboards de monitoring.
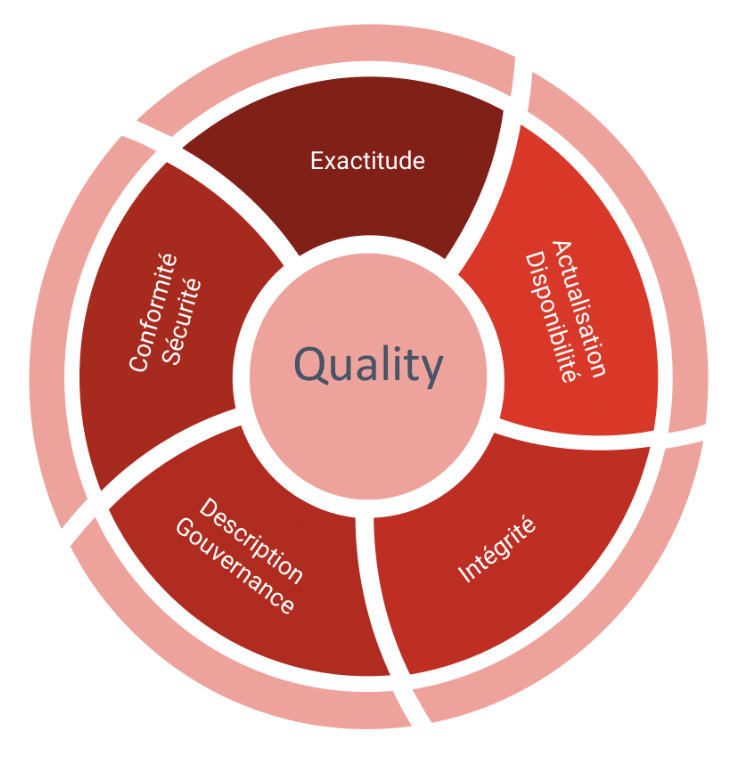
- Exactitude
Des données de bonne qualité commencent par être le reflet de la vérité. Et cela doit pouvoir se mesurer directement avec le système source. Il est alors possible de contrôler également la complétude des données.
- Actualisation / disponibilité
Mais une donnée exacte, si elle n’est pas actualisée régulièrement,risque de devenir obsolète et perdre toute utilité. Afin de pouvoir saisir toutes les opportunités, les données devront être disponibles au fur et à mesure de leur production , en cohérence avec les besoins des utilisateurs, allant du temps réel à J+1 généralement.
- Intégrité
Dans un objectif d’unicité des informations à l’échelle de l’entreprise, il convient de s’assurer qu’il n’y ait pas de doublons présents dans les données ni même dans les datasets exposés. Il est aussi important de garantir que les données de tous les systèmes de l’organisation soient bien synchronisées.
Couvrir un historique de données suffisant ainsi qu’une granularité fine pourra servir tous les besoins de calcul.
- Description / Gouvernance
La qualité descriptive des données réside dans leur facilité de localisation, leur interprétabilité et leur représentation cohérente. Afin de pouvoir garantir un accès facilité à la donnée, une entreprise doit être capable de retracer le lineage complet d’une donnée exposée, ceci jusqu’à sa source.
Des données décrites dans chaque couche de stockage seront facilement manipulées par les utilisateurs.
- Conformité / Sécurité
Enfin, les données, afin de servir au mieux la stratégie de l’entreprise, doivent respecter les normes et les règlements en vigueur dans l’espace où elles sont utilisées et être sécurisées de bout en bout en termes d’accès et de transport.
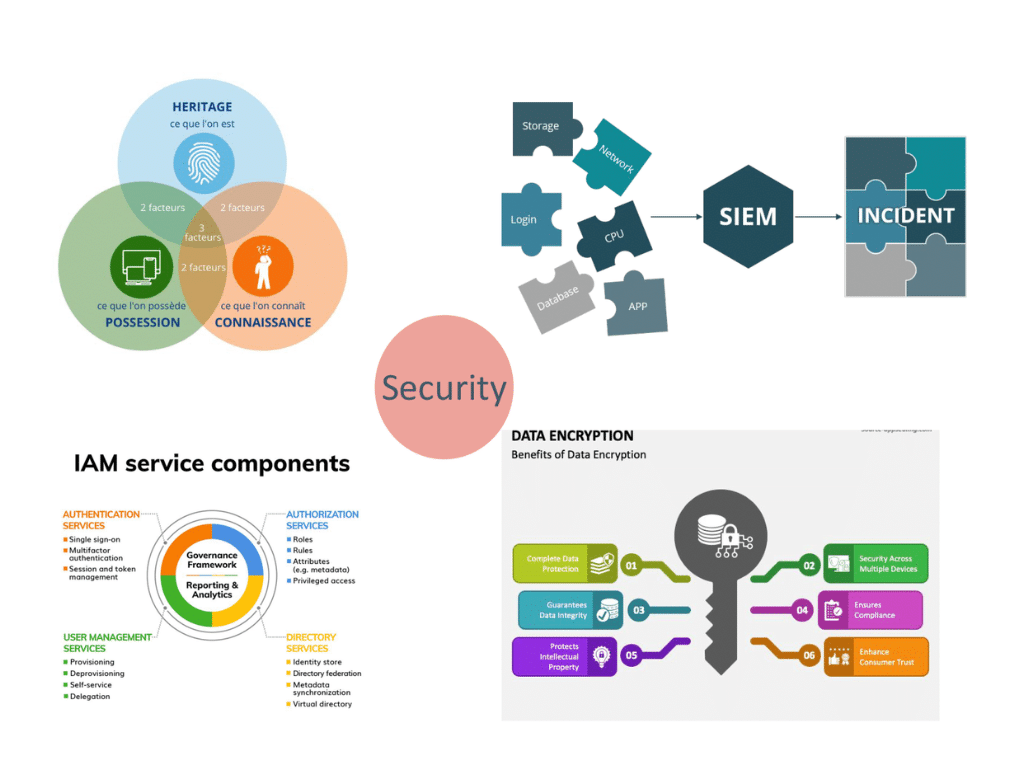
Mise en place de mesures de sécurité
La mise en place de mesures de sécurité pour protéger les données contre les accès non autorisés, la divulgation, la modification ou la destruction est essentielle. Ces mesures peuvent être techniques et contraignantes, elles peuvent également être organisationnelles et revues par du contrôle continu ou a posteriori. Il faudra outiller l’access management à minima puis dans un second temps la surveillance de ces accès au travers d’un SIEM (Security Information Event Manager).
Politique d'accès et outillage
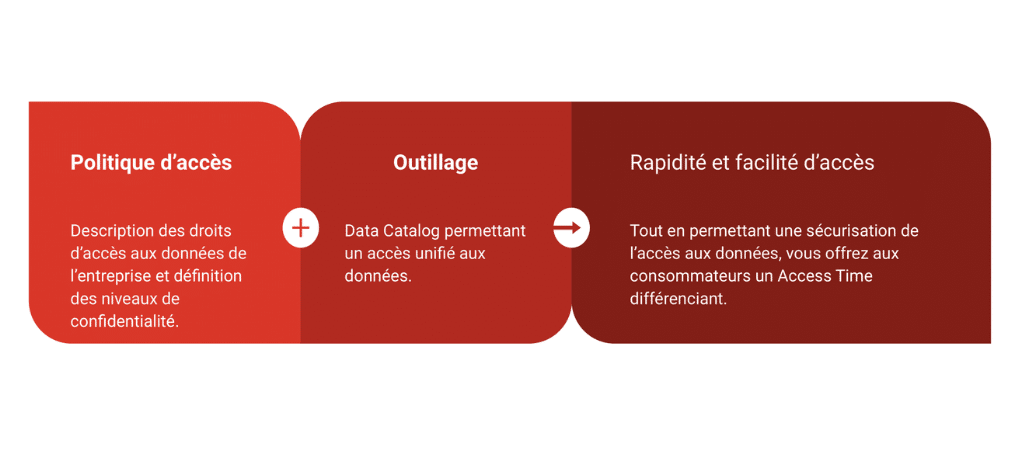
La mise à disposition d’une politique d’accès aux données et d’un outillage dédié permettra aux consommateurs de trouver et d’utiliser les données dont ils ont besoin avec facilité et rapidité. Celle-ci peut relever par exemple des niveaux de confidentialité ou encore de la gestion des autorisations délivrées automatiquement en fonction du contexte métier / utilisateur.
L’un des points importants qu’il faudra garder dans le viseur est la sensibilisation des parties prenantes à l’importance de la gouvernance des données et les former aux processus et aux outils mis en place.
Standardisation
Il est admis qu’adopter des formats et des protocoles standardisés pour l’échange de données en utilisant des formats et des protocoles communs est une bonne pratique afin que les différents systèmes et applications puissent échanger des données de manière efficace.
Format de données
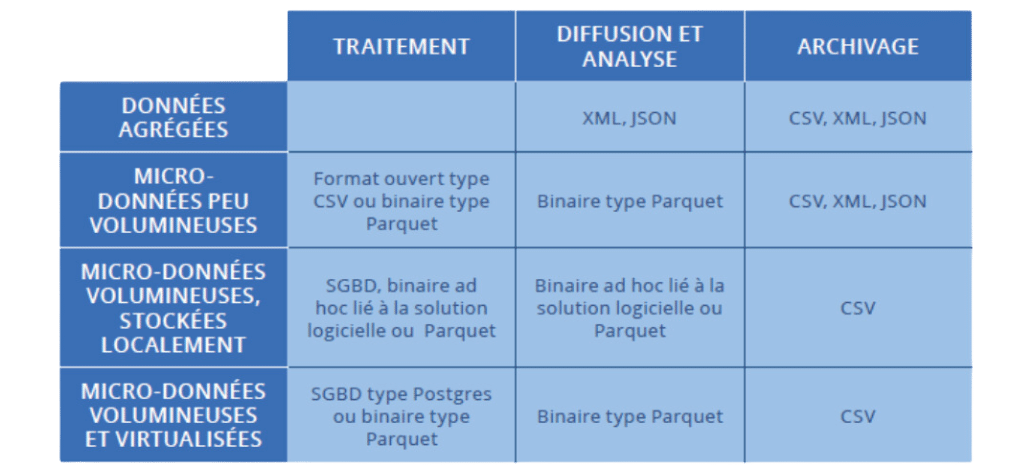
Il existe de nombreux formats de données différents, chacun ayant ses propres avantages et inconvénients. Quelques exemples de formats de fichiers les plus courants :
- CSV (Comma-Separated Values) : Format simple et largement utilisé pour stocker des données tabulaires.
- JSON (JavaScript Object Notation) : Format léger et facile à utiliser pour stocker des données structurées.
- Fichiers binaires : Formats spécifiques à une application pour stocker des données non structurées, comme des images ou des vidéos, ou structurées (Avro).
L’entreprise peut choisir de mettre en œuvre un seul ou plusieurs standards en fonction de son contexte technologique et des compétences des équipes.
Protocoles de communication
Les protocoles de communication définissent les règles et les procédures pour l’échange de données entre deux systèmes. Parmi les protocoles les plus courants en matière d’échange de données, on peut citer :
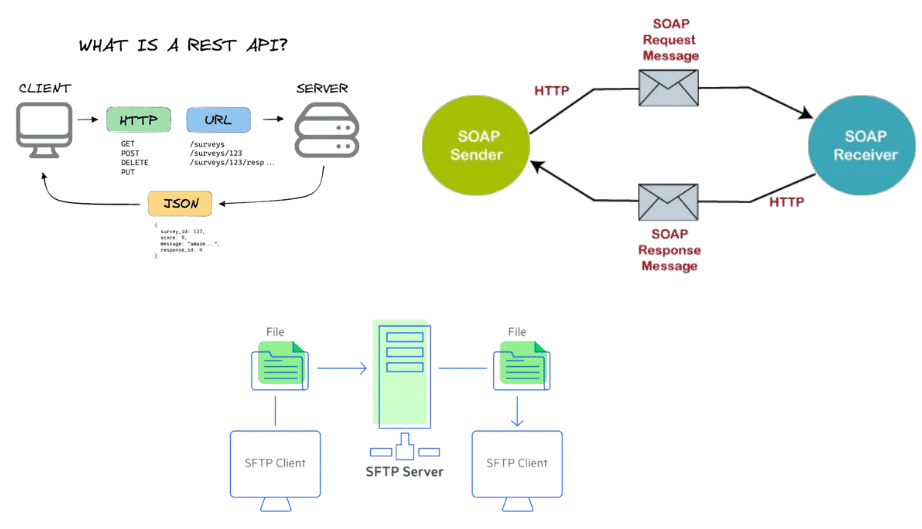
- FTP (File Transfer Protocol): Protocole utilisé pour le transfert de fichiers.
- SOAP (Simple Object Access Protocol): Protocole utilisé pour l’échange de messages XML entre des applications Web.
- REST (Representational State Transfer): Architecture logicielle pour les services Web.
Les entreprises seront souvent amenées à mettre en œuvre plusieurs protocoles de communication afin de pouvoir traiter leurs échanges de données avec la temporalité nécessaire à chaque cas d’usage (Batch vs Real Time).
Couche sémantique
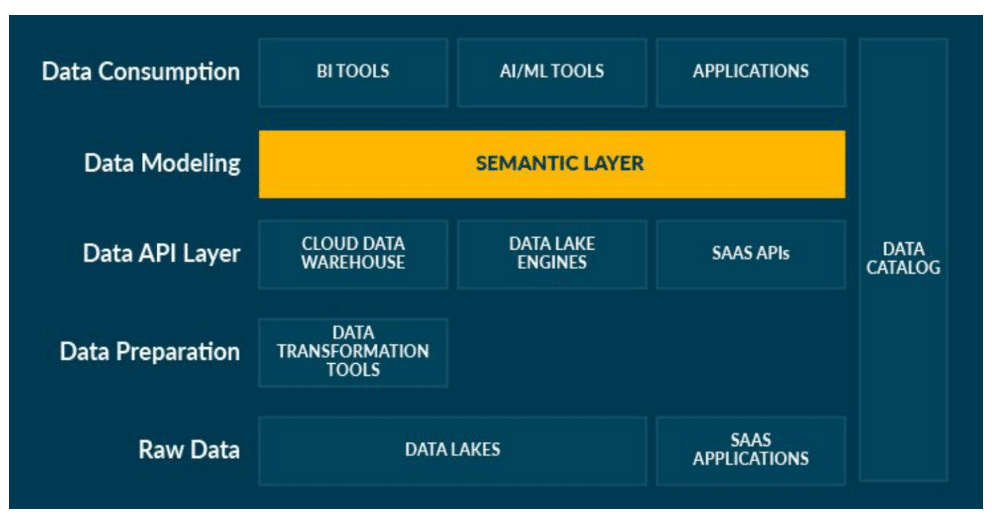
La mise en place d’une couche sémantique dans l’exposition des données aux consommateurs doit permettre l’utilisation d’un vocabulaire commun dont le rôle sera de faire le pont entre la terminologie informatique, parfois contrainte par les systèmes sources, et les expressions métier de cette même donnée, en agissant comme une table de traduction.
L’utilisation de schémas décrivant les liens entre les données aidera également à la compréhension des données exposées. Le tout permettra d’associer facilement une signification aux données et de les positionner dans un domaine de connaissances.
Le second avantage à utiliser une couche sémantique réside dans la faculté d’exposer un modèle de données commun empêchant la survenue de problèmes d’écarts de données dû à l’utilisation de différentes sources de données.
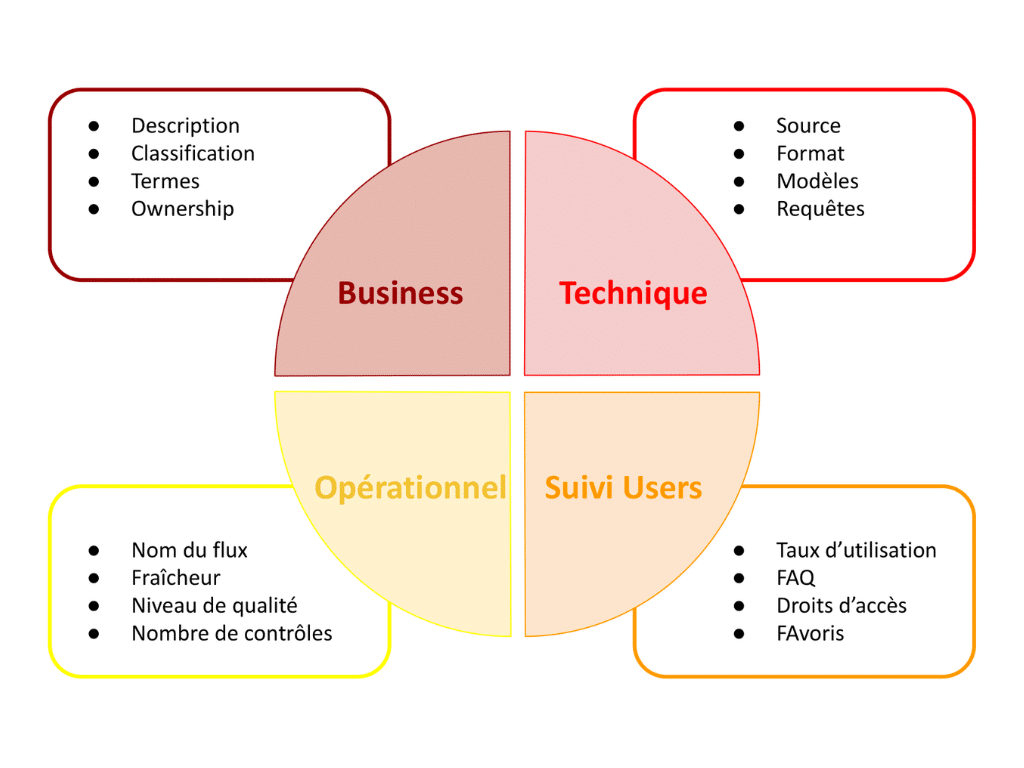
Métadonnées
Les métadonnées servent à enrichir les données pour en faciliter la compréhension et l’utilisation. Il s’agit pour cela d’ajouter des informations, généralement sous forme de tags ou de labels, pour les décrire et les contextualiser. Il est possible d’ajouter des natures d’information très diverses dont les types seront le plus généralement : Business, Technique, Opérationnel, Suivi Utilisateur. – cf schéma.
Cela aura également pour effet d’améliorer la recherche et la découverte des données mais aussi a fortiori leur utilisation dans l’analyse et pour la prise de décision.
Il conviendra d’alimenter le plus possible les métadonnées automatiquement dès lors que les outils le permettent, mais il sera nécessaire d’investir du temps dans l’ajout manuel de ces dernières par les Technical Owners et Business Owners, car sans cet effort de documentation, le pari de la démocratisation des données est perdu d’avance.
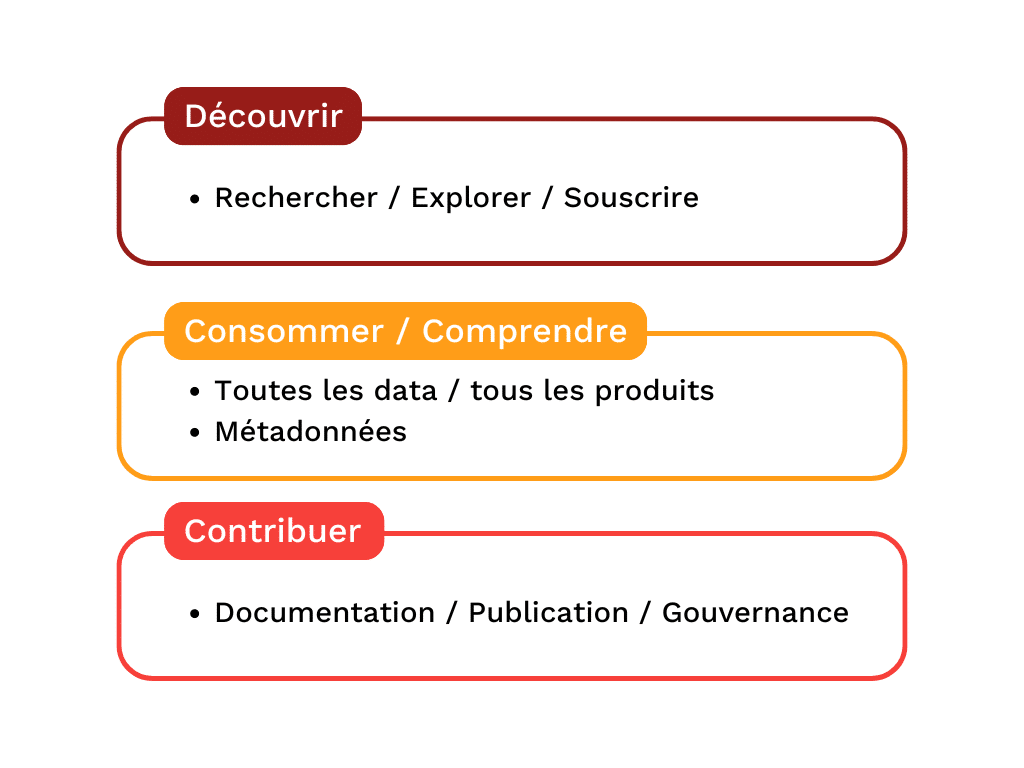
Outils et technologies
La garantie d’une interopérabilité des données complète et efficace passe par la mise en place d’un socle technologique commun, partagé et mutualisé. Il sera constitué de différents outils permettant d’adresser les objectifs cités précédemment, mis à disposition sous formes de produits self-service facilitant les usages :
Le Catalogue de données
L’un des besoins à adresser prioritairement sera sans doute le Catalogue de données unique, permettant à toutes les parties prenantes de se retrouver en un point central.
D’une part les producteurs de données pour référencer, documenter et gouverner les données, d’autre part les consommateurs de données pour explorer, rechercher, et souscrire à l’utilisation des données. Il devra permettre de gérer tous les types de métadonnées définis comme étant mandatory par la gouvernance.
Pipeline de données
En second lieu, l’utilisation d’un outil de pipeline de données commun apportera des bénéfices substantiels dans la mise en oeuvre réussie de l’interopérabilité de vos données.
Un ELT/ETL mutualisé permettra de simplifier les échanges de données et alignera tous les utilisateurs sur des protocoles et moyens de déclenchements unifiés.
Cette mutualisation vise à permettre aux différents domaines de l’entreprise de provisionner des ressources techniques à la demande pour la conception et l’exploitation de leurs produits de données, ceci de façon simple et homogène, de sorte à faciliter la maintenance de tous les produits.
Nous adressons un double objectif grâce à cette logique en rationalisant le socle et les technologies utilisées à travers l’entreprise.
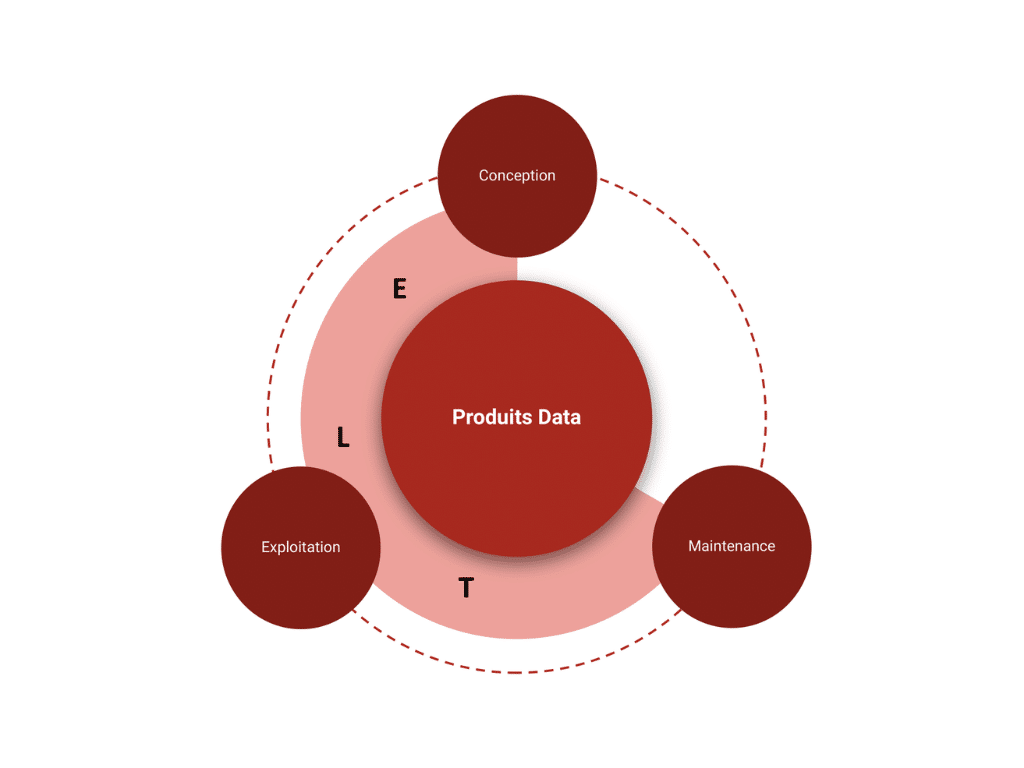
Deux éléments essentiels sont à prendre en compte lorsque vous pensez votre architecture autour de ce socle commun :
- Évaluer votre environnement technologique en tenant compte des systèmes et applications existants mais aussi et surtout des compétences internes et des budgets disponibles à court, moyen et long terme.
- Choisir une solution évolutive en privilégiant des solutions capables de s’adapter à l’évolution de vos besoins, le moins vendorlocked possible voire cloud provider agnostique.
Culture du partage
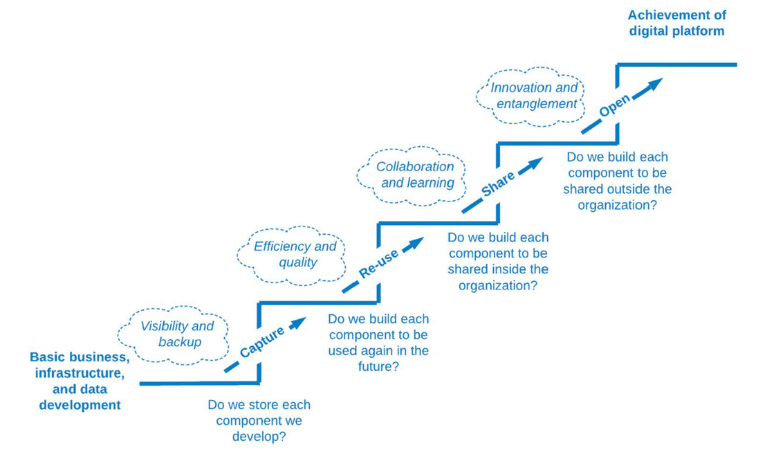
Dernier aspect favorisant l’interopérabilité (des données) en entreprise, mais pas des moindres.
L’encouragement d’une culture du partage et de la collaboration entre les différents services de l’entreprise au travers de l’innersourcing, mais aussi de la mise en place de communautés transverses, permettra de stimuler l’innovation au sein des équipes.
Conclusion
Nous pouvons constater, à la lecture de cet article, que les entreprises sont face à un vaste chantier lorsqu’il s’agit de l’interopérabilité des données.
Les parties prenantes sont nombreuses et leurs souhaits sont parfois compliqués à réconcilier au sein d’une même politique. C’est un véritable enjeu d’adoption qu’il faut gérer via un plan d’acculturation adapté favorisant ainsi la fédération des différentes équipes sur la ligne de conduite à adopter.
Ces efforts de convergence des pratiques ont alors un effet bénéfique visant à simplifier la collaboration et les développements ce qui conduira à démocratiser l’usage des données.
Dans le même temps, des économies d’échelle pourront être constatées sur le build mais aussi le run des solutions mises en œuvre dans le respect de la politique commune.
Deux éléments essentiels seront toujours à prendre en compte lorsque vous penserez à votre architecture autour de ce socle commun :
- Évaluer votre environnement technologique en tenant compte des systèmes et applications existants mais aussi et surtout des compétences internes et des budgets disponibles à court, moyen et long terme.
- Choisir des solutions capables de s’adapter à l’évolution de vos besoins, le moins vendorlocked possible voire cloud provider agnostique.