Smart Innovation :Les réseaux de neurones récurrents
Introduction
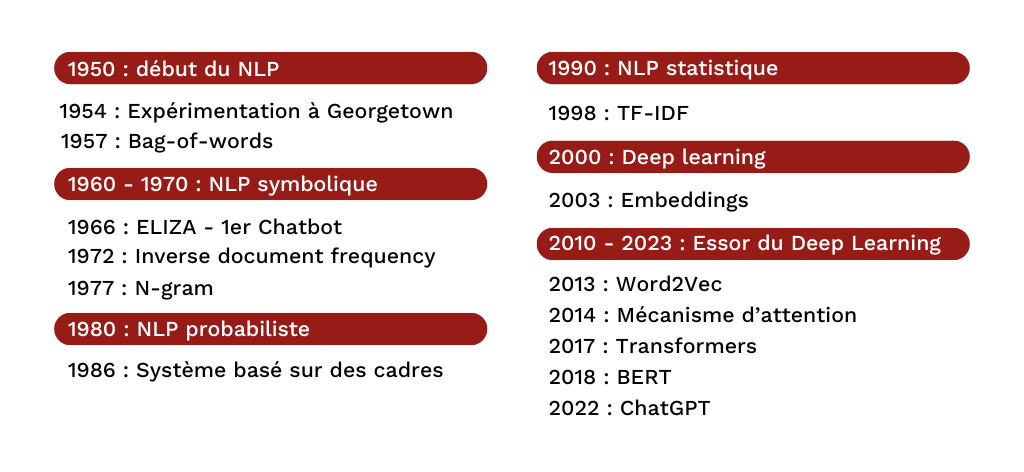
Le traitement automatique du langage naturel (NLP) a parcouru un long chemin, transformant la manière dont les machines analysent et comprennent le texte. Dans ses débuts, le NLP reposait sur des méthodes comme le Bag of Words (BoW), qui modélisaient le texte par des représentations simples mais limitées, en ignorant l’ordre des mots. Plus tard, les word embeddings tels que Word2Vec et GloVe ont marqué une avancée en capturant les relations sémantiques entre les mots, introduisant ainsi une compréhension contextuelle.
Ces progrès ont toutefois révélé la nécessité de méthodes capables de saisir la structure séquentielle du langage, une qualité essentielle pour traiter des tâches complexes comme la traduction automatique ou la synthèse de texte. C’est dans ce contexte que les réseaux neuronaux récurrents (RNN) ont émergé, apportant une solution capable d’analyser et de conserver l’information au fil des mots dans une phrase. Dans cet article, nous allons explorer comment les RNN et leurs variantes ont révolutionné le NLP en apportant une compréhension contextuelle approfondie, ouvrant ainsi la voie aux modèles modernes de traitement du langage.
RNN : Définition et concept
Les RNNs (recurrent neural network ou réseaux de neurones récurrents en français) sont des architectures de réseaux de neurones adaptés pour le traitement des données séquentielles.
Une séquence est un ensemble de données définis dans un ordre bien particulier.
Par exemple :
Données de Time Series (Ventes)
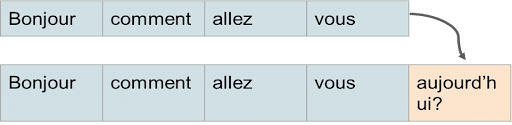
Phrases
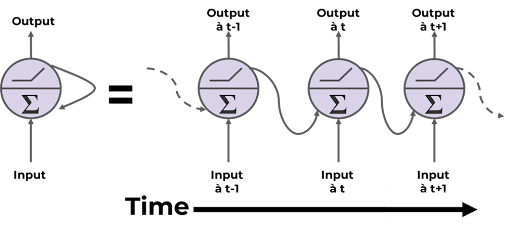
Particularité d’un RNN :
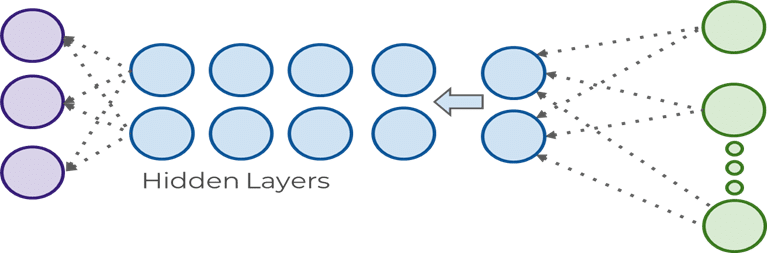
Contrairement aux réseaux feed-forward classiques, un RNN possède des boucles qui lui permettent de mémoriser des informations d’une étape précédente pour influencer les suivantes. Ils possèdent donc un vecteur mémoire qui à pour rôle de retenir des informations d’une étape précédente pour prendre des décisions à l’étape actuelle.
Limites et problèmes :
La présence d’états cachés et de boucles entièrement connectées engendre deux problèmes majeurs :
Vanishing Gradient
Les gradients deviennent très petits lors de la rétropropagation sur de longues séquences, rendant l’apprentissage difficile.
- Impact : Le réseau devient incapable de mémoriser les informations qui se trouvent loin dans la séquence.
Exploding Gradient
Les gradients deviennent excessivement grands, conduisant à des poids instables.
- Impact : Lorsque les gradients explosent, le modèle devient incontrôlable et génère des erreurs gigantesques, rendant l’entraînement difficile à stabiliser.
LSTM :
La cellule LSTM (Long Short-Term Memory) a été créée pour aider à résoudre les problèmes des RNN.
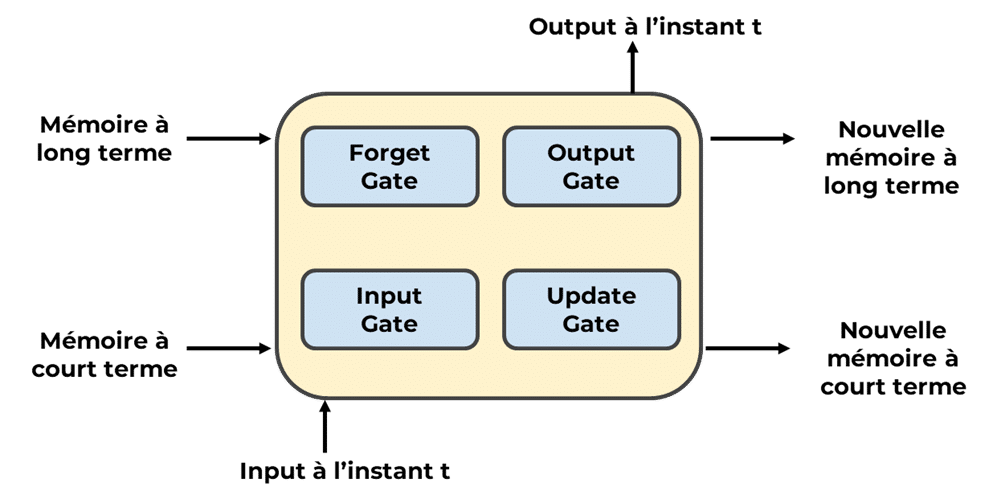
Fonctionnement :
Forgate Gate
Elle décide quelles informations de la cellule de mémoire précédente doivent être oubliées. Si l’information est inutile, la porte d’oubli met la mémoire à zéro.
Input Gate
Elle contrôle quelles nouvelles informations sont ajoutées à la cellule de mémoire. Ces informations proviennent de l’entrée actuelle et de l’état caché précédent.
Output Gate
Elle sélectionne quelles informations de la cellule de mémoire doivent être extraites pour l’état caché actuel.
GRU :
Les GRU sont une variante simplifiée des LSTM, avec des performances similaires, mais avec une structure légèrement plus simple. Ils ne sont composés que d’une porte de réinitialisation similaire à la porte d’oubli pour les LSTM et d’une porte de mise à jour similaire à la porte d’entrée et de sortie combinées.
Mise en pratique (GenAI) :
Nous avons créer un réseau de neurones qui génère de nouveaux textes à partir d’un corpus de données textuelles
But : Étant donné une séquence de chaîne d’entrée, prévoyez la séquence décalée d’un caractère vers l’avant.
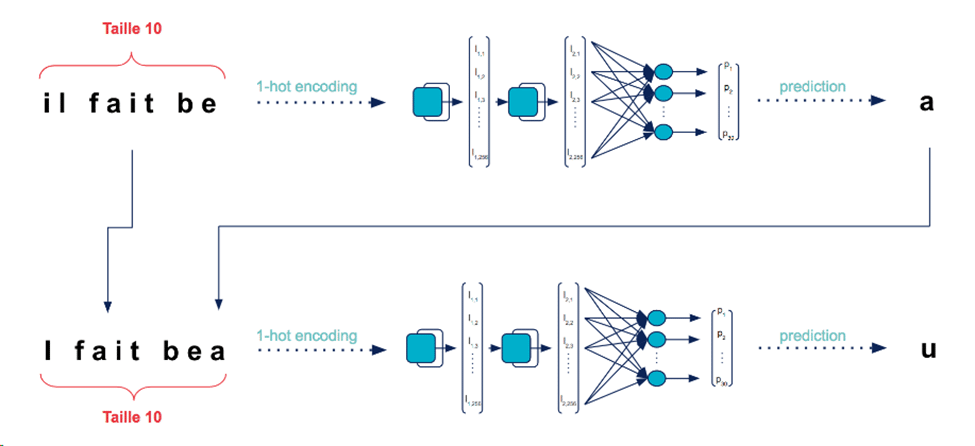
Dans notre exemple, nous utiliserons les œuvres de William Shakespeare en anglais.
Le RNN basé sur les caractères va en fait apprendre la structure de l’écriture des pièces et aussi l’espacement, juste au niveau du caractère !
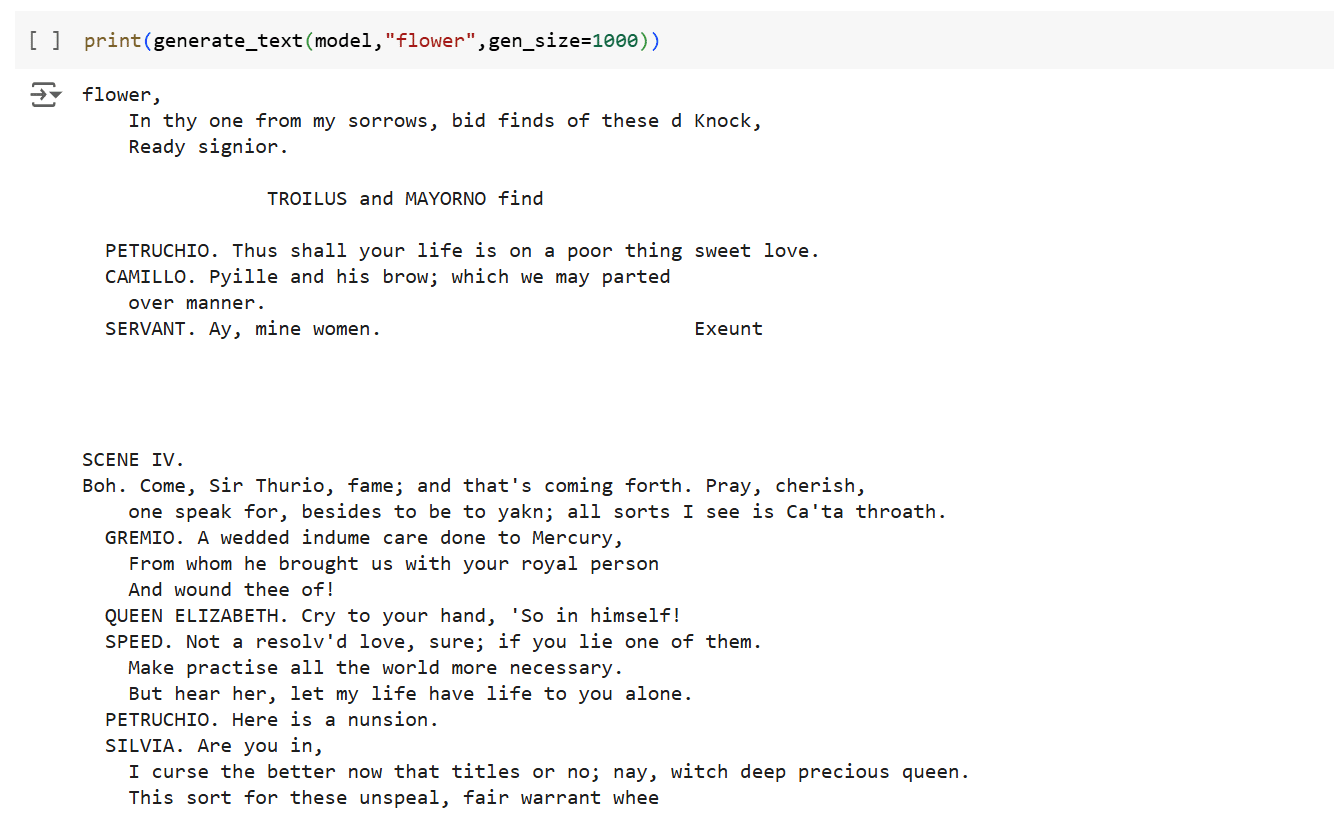
On obtient après apprentissage un modèle capable de générer avec une assez bonne précision des texte similaires à celui de la pièce de Shakespeare.
Conclusion
Bien que les RNN, LSTM et GRU soient désormais accompagnés de modèles plus récents, ils restent essentiels pour comprendre les bases du NLP moderne. Leur capacité à apprendre les dépendances séquentielles a été une avancée décisive pour le traitement automatique du langage, inspirant et influençant profondément les technologies de pointe d’aujourd’hui.