
Détection de Doublons Retail : De l’audit Power BI à l’industrialisation GCP
Détection de Doublons Retail : De l’Audit Power BI à l’Industrialisation GCP
![]()
![]()
Lorsqu’on aborde la qualité des données dans le retail, la question n’est jamais de savoir s’ il y a des doublons, mais combien ils coûtent réellement. C’est tout l’enjeu du diagnostic architectural : transformer une impression diffuse (« on a des soucis de qualité ») en une métrique actionnable. C’est précisément le défi relevé pour l’un de nos clients grands comptes, enseigne bien connue du retail, dont le référentiel de 1,6 million de clients hébergé sur Google Cloud Platform (GCP) nécessitait un audit en profondeur.
L’analyse a révélé près de 110 000 comptes actifs en doublon (soit un taux de friction de 1,61%). Au-delà du simple stockage, ce chiffre se traduit par une perte sèche annuelle estimée à 5 000 € rien que sur le canal emailing, sans compter la vision client fragmentée qui rend inopérant tout effort de personnalisation marketing.
1. Le Diagnostic : Pourquoi le SQL ne suffit plus
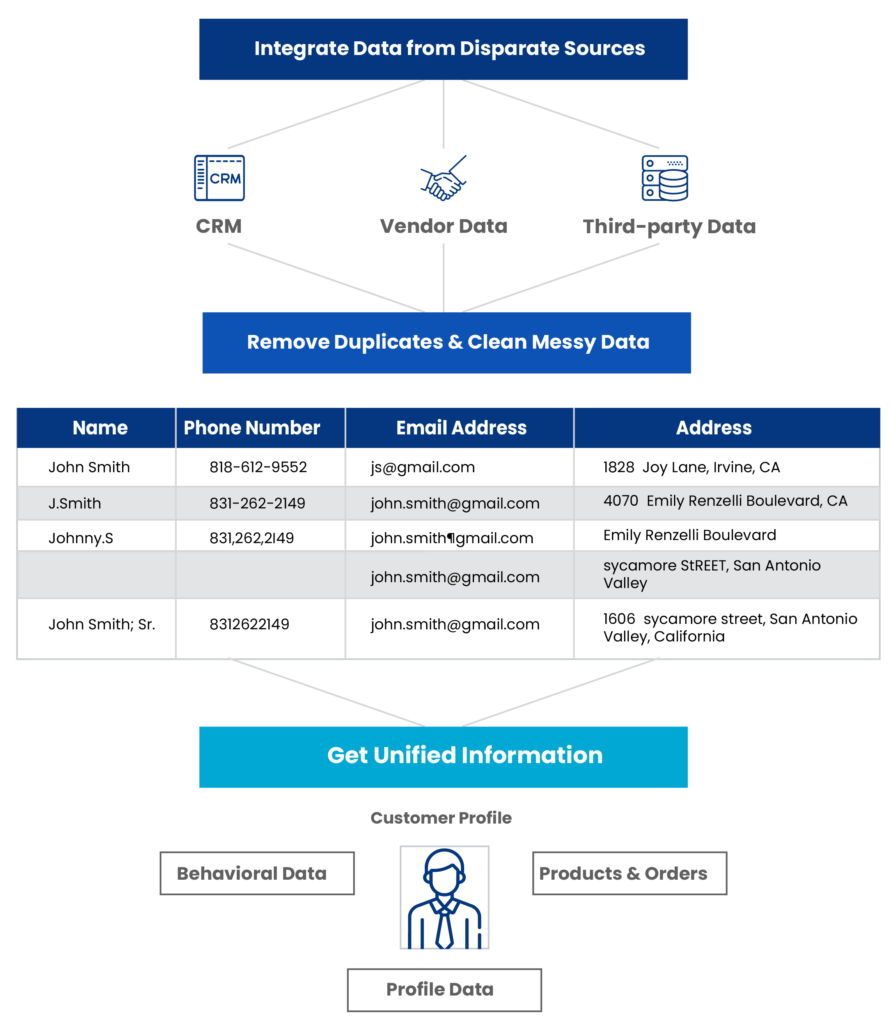
La première limite rencontrée dans ce type de projet est souvent méthodologique. L’approche traditionnelle par « matching exact » (SQL strict sur nom/prénom/email) échoue systématiquement face à la réalité humaine de la saisie en magasin ou en ligne.
L’audit des données client a mis en lumière les cas d’usage typiques qui passent sous les radars d’une requête classique :
- Variations phonétiques et fautes de frappe : Un « gmel.com » au lieu de « Gmail.com » est techniquement différent, mais représente la même intention.
- Formats hétérogènes : Le classique préfixe international (+33 vs 06) qui casse les clés de jointure.
- Évolutions d’identité : Les changements de noms (mariage, usage) qui créent des identités parallèles.
Face à ces contraintes, l’utilisation d’un algorithme de matching probabiliste (fuzzy logic), capable d’attribuer un score de confiance plutôt qu’un résultat binaire, s’est imposée comme une nécessité technique.
2. Architecture Hybride : Le tandem Power BI & Python

Pour prototyper rapidement cette logique sans lancer un chantier d’infrastructure lourd, le choix s’est porté sur une architecture hybride : utiliser Power BI non pas seulement comme outil de visualisation, mais comme orchestrateur léger d’un script Python.
La mécanique d’intégration
- Le principe repose sur l’injection de la puissance de transformation de Python au sein du pipeline Power Query. Concrètement, Power Query assure le nettoyage préliminaire (ETL) et passe la main à un script Python via un DataFrame pandas.
Ce choix architectural nécessite quelques prérequis sur le poste de développement :
- Un environnement Python standard.
- Les bibliothèques pandas et numpy (socle de manipulation des DataFrames).
- Une gestion fine des droits d’exécution locaux.
Le pipeline technique s’est d’ailleurs appuyé sur l’IA générative pour initier les premières versions de l’algorithme de matching, ensuite raffinées par itérations successives pour s’adapter aux spécificités du dataset du client.
Le piège du casting silencieux
Un point de vigilance est apparu lors de l’intégration : la conversion des types de données entre le moteur Power BI et Python. Le cas des numéros de téléphone est le plus significatif.
Lors du passage du dataset vers Python, Power BI a tendance à interpréter les colonnes numériques, même si elles sont des identifiants (comme un numéro de téléphone). Résultat : les chaînes « 0612… » sont castées en entiers « 612… », perdant le zéro non significatif. Cette altération rend le matching impossible.
La « ruse » technique contournant ce comportement consiste à préfixer artificiellement les champs sensibles (par exemple avec un « + ») dans Power Query pour forcer le typage texte, puis à nettoyer ce préfixe une fois les données chargées dans le script Python.
3. Gouvernance : La donnée client n’est pas une donnée comme les autres
Traiter des données PII (Personally Identifiable Information) impose une rigueur absolue. L’audit a mis en exergue que la technologie ne peut pas tout résoudre si la gouvernance des données en amont est défaillante.
Le profiling des données a révélé des pratiques métier génératrices de dette technique :
- Saisies « bouchon » : L’usage de numéros fictifs (+00, 123456) pour contourner les champs obligatoires en caisse.
- Interfaces permissives : Des formulaires web ou caisse créant des doublons par défaut, faute de contrôle d’existence préalable.
Il semble pertinent d’instaurer des standards de normalisation stricts en amont de tout traitement algorithmique : formatage E.164 pour les téléphones (+33), validation des domaines MX pour les emails, et nettoyage des caractères spéciaux. C’est ce travail de fond sur la standardisation qui garantit la pertinence du score de confiance final.
4. Stratégie d’Industrialisation : Du Labo à l’Usine
Si l’architecture Power BI + Python est idéale pour l’audit et le prototypage (le « Lab »), elle montre vite ses limites en production. Pour traiter les 1,6 million d’enregistrements du client, le refresh Power BI nécessitait entre 5 et 6 heures. Ce temps de traitement s’explique par l’overhead mémoire massif généré par le transfert des données entre le moteur M de Power BI et l’environnement Python.
L’architecture cible sur GCP
Pour passer à l’échelle, l’architecture a dû être découplée :
- Traitement (Compute) : Le script Python, validé en phase POC, est porté en script standalone sur Google Cloud Platform. Exécuté en batch, il traite la volumétrie en quelques minutes.
- Stockage : Les résultats (paires de doublons et scores) sont persistés dans une table dédiée (BigQuery ou SQL).
- Visualisation : L’outil BI (ici Qlik, selon la stack client) se connecte en lecture seule sur cette table pré-calculée.
Cette approche de pipeline permet de séparer le cycle de vie du calcul (lourd, périodique) de celui de la restitution (rapide, à la demande).
5. ROI et Vision Long Terme
L’opération a permis de quantifier le ROI immédiat : réduction des coûts de stockage, économies sur les campagnes marketing (email/SMS), et surtout, une base saine pour réactiver le ciblage client.
Cependant, le nettoyage de données n’est pas une action ponctuelle. La recommandation stratégique porte sur la mise en place de cycles itératifs :
- Monitoring : Surveiller l’apparition de nouveaux doublons post-nettoyage.
- Root Cause Analysis : Remonter à la source (interfaces, formation des vendeurs) pour tarir le flux de création de doublons.
- Scalabilité : Adopter des architectures cloud-natives capables d’absorber la croissance organique des bases retail.
L’expertise Data de NTICO
Chez NTICO, nous abordons ces projets avec une double casquette : technique et métier. Notre expérience sur la mise en place de Data Platforms d’envergure nous permet de naviguer de l’audit initial jusqu’à l’industrialisation complexe.
Nous ne nous contentons pas de fournir un script ; nous construisons l’architecture de données qui soutient votre croissance. Que ce soit sur des problématiques de gouvernance, d’orchestration DataOps ou d’architectures hybrides, nos équipes transforment vos contraintes de qualité de données en leviers de performance opérationnelle.

IA SUMMIT
IA SUMMIT
Ce mardi, nos CollabsAuTop ont participé à la première édition lilloise de La Cité de l’IA ! 💡
Jean vous emmène revivre cette journée, entre key notes, cas d’usages et animations ! 🎬
Et en bonus : retrouvez le témoignage de Xavier, Product Owner chez Ntico, qui partage son retour sur l’événement ! 👀




L'Agentic AI - Smart Data by Ntico
SMART DATA
L'Agentic AI
Les agents IA représentent une évolution majeure dans le domaine de l’intelligence artificielle ! 🎯
Ces systèmes intelligents ne se contentent plus de répondre à des instructions : ils agissent de façon autonome, s’adaptent à leur environnement et apprennent en continu. 🚀
Découvrez dans cet article de la communauté SmartData by Ntico comment les agents IA peuvent transformer vos métiers et accélérer votre transformation digitale 🔍👇
Construction d'une Self Serve Data Platform - Livre blanc Smart Data by Ntico
LIVRE BLANC
Construction d'une Self Serve Data Platform
La Communauté SmartData by Ntico publie son premier livre blanc autour de La Construction d’une Self Serve Data Platform !
Insights pratiques, recommandations, retours d’expériences… Découvrez comment une plateforme de données autonome, booste l’agilité et la gestion des données au sein des équipes ! 🚀
Si vous êtes intéressés par la gestion des données et la mise en place de solutions d’automatisation, ce livre blanc vous sera forcément utile !
N’hésitez pas à partager vos retours ! 📩

Bilan 2024 - SmartData by Ntico
Bilan 2024
Introduction
2024 : une année riche en innovations pour la communauté SmartData by Ntico ! Nos équipes ont travaillé sur des projets variés, utilisant des technologies performantes pour relever les défis de nos clients et transformer les données en leviers stratégiques. Découvrez nos réalisations 2024 !
Catégorie 1 : Optimisation et Data Quality
Montées de version
Améliorer les outils et systèmes pour répondre aux nouvelles exigences.

Création de Datahub centralisé
Unifier les données pour une vision globale et cohérente.

Optimisation des flux
Fluidifier les échanges pour maximiser la performance des données.

Implémentation Rapport Data Quality
Assurer la fiabilité des données avec des outils de qualité.

Catégorie 2 : Ingénierie et modélisation des données
Data engineering, CRM & encaissement
Optimiser la gestion client et les processus d’encaissement grâce aux données.

Product Data Engineering
Aligner les données produits avec les objectifs stratégiques.

Mise en place d'un nouvel ELT et alimentation DWH
Moderniser les pipelines de données pour alimenter la data warehouse.

Data engineering tribe stocks
Optimiser la gestion des stocks à l’aide de la data engineering

Catégorie 3 : Plateformes et référentiels de données
Référentiel Data RH
Structurer les données RH pour une gestion simplifiée et centralisée.

Self Service DataPlatform
Rendre les données accessibles à tous en toute autonomie.
Socle Data Engineering Platform
Fournir une plateforme solide pour soutenir tous les projets data.

Nouveau socle de données
Poser les bases d’une infrastructure data robuste et évolutive.

Rationalisation stack technique
Simplifier l’écosystème technologique pour plus d’efficacité.

Catégorie 4 : Business Intelligence et IA
Suivi données d'orchestration
Piloter efficacement les opérations grâce à un suivi data optimisé.

Projets décisionnels
Transformer les données et les insights stratégiques pour une prise de décision éclairée.

Suivi activité industrielle
Analyser les données pour optimiser la production et les performances.

Modèle prédictif de palettisation
Prédire et planifier les besoins logistiques avec précision.
Conclusion
2024 a confirmé notre capacité à transformer les données en solutions concrètes et impactantes.
Grâce à un écosystème technologique diversifié et à l’implication de nos collaborateurs, nous avons consolidé notre rôle de partenaire de confiance pour accompagner la transformation numérique de nos clients !
Partagez les technologies qui ont marqué vos projets cette année ! Nous serions ravis d’échanger avec vous !

Les réseaux de neurones récurrents - SmartData by Ntico
Smart Innovation :
Les réseaux de neurones récurrents
Introduction
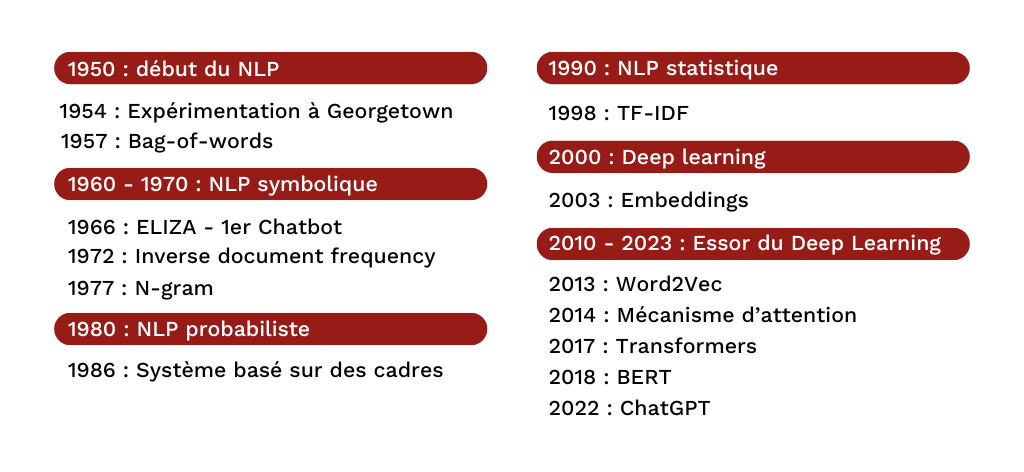
Le traitement automatique du langage naturel (NLP) a parcouru un long chemin, transformant la manière dont les machines analysent et comprennent le texte. Dans ses débuts, le NLP reposait sur des méthodes comme le Bag of Words (BoW), qui modélisaient le texte par des représentations simples mais limitées, en ignorant l’ordre des mots. Plus tard, les word embeddings tels que Word2Vec et GloVe ont marqué une avancée en capturant les relations sémantiques entre les mots, introduisant ainsi une compréhension contextuelle.
Ces progrès ont toutefois révélé la nécessité de méthodes capables de saisir la structure séquentielle du langage, une qualité essentielle pour traiter des tâches complexes comme la traduction automatique ou la synthèse de texte. C’est dans ce contexte que les réseaux neuronaux récurrents (RNN) ont émergé, apportant une solution capable d’analyser et de conserver l’information au fil des mots dans une phrase. Dans cet article, nous allons explorer comment les RNN et leurs variantes ont révolutionné le NLP en apportant une compréhension contextuelle approfondie, ouvrant ainsi la voie aux modèles modernes de traitement du langage.
RNN : Définition et concept
Les RNNs (recurrent neural network ou réseaux de neurones récurrents en français) sont des architectures de réseaux de neurones adaptés pour le traitement des données séquentielles.
Une séquence est un ensemble de données définis dans un ordre bien particulier.
Par exemple :
Données de Time Series (Ventes)
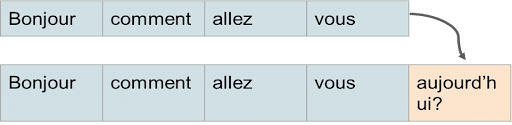
Phrases
Particularité d’un RNN :
Contrairement aux réseaux feed-forward classiques, un RNN possède des boucles qui lui permettent de mémoriser des informations d’une étape précédente pour influencer les suivantes. Ils possèdent donc un vecteur mémoire qui à pour rôle de retenir des informations d’une étape précédente pour prendre des décisions à l’étape actuelle.
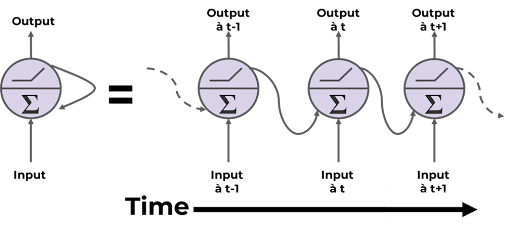
Limites et problèmes :
La présence d’états cachés et de boucles entièrement connectées engendre deux problèmes majeurs :
Vanishing Gradient
Les gradients deviennent très petits lors de la rétropropagation sur de longues séquences, rendant l’apprentissage difficile.
- Impact : Le réseau devient incapable de mémoriser les informations qui se trouvent loin dans la séquence.
Exploding Gradient
Les gradients deviennent excessivement grands, conduisant à des poids instables.
- Impact : Lorsque les gradients explosent, le modèle devient incontrôlable et génère des erreurs gigantesques, rendant l’entraînement difficile à stabiliser.
LSTM :
La cellule LSTM (Long Short-Term Memory) a été créée pour aider à résoudre les problèmes des RNN.
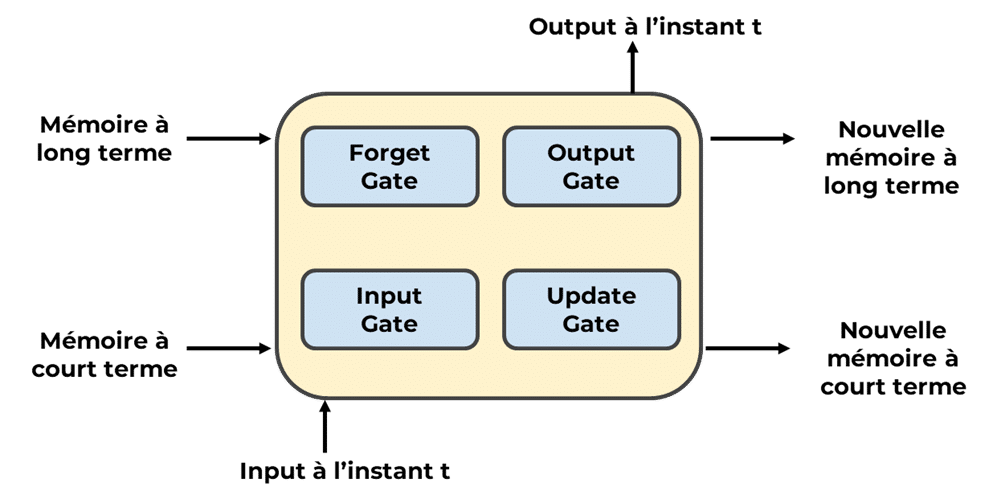
Fonctionnement :
Forgate Gate
Elle décide quelles informations de la cellule de mémoire précédente doivent être oubliées. Si l’information est inutile, la porte d’oubli met la mémoire à zéro.
Input Gate
Elle contrôle quelles nouvelles informations sont ajoutées à la cellule de mémoire. Ces informations proviennent de l’entrée actuelle et de l’état caché précédent.
Output Gate
Elle sélectionne quelles informations de la cellule de mémoire doivent être extraites pour l’état caché actuel.
GRU :
Les GRU sont une variante simplifiée des LSTM, avec des performances similaires, mais avec une structure légèrement plus simple. Ils ne sont composés que d’une porte de réinitialisation similaire à la porte d’oubli pour les LSTM et d’une porte de mise à jour similaire à la porte d’entrée et de sortie combinées.
Mise en pratique (GenAI) :
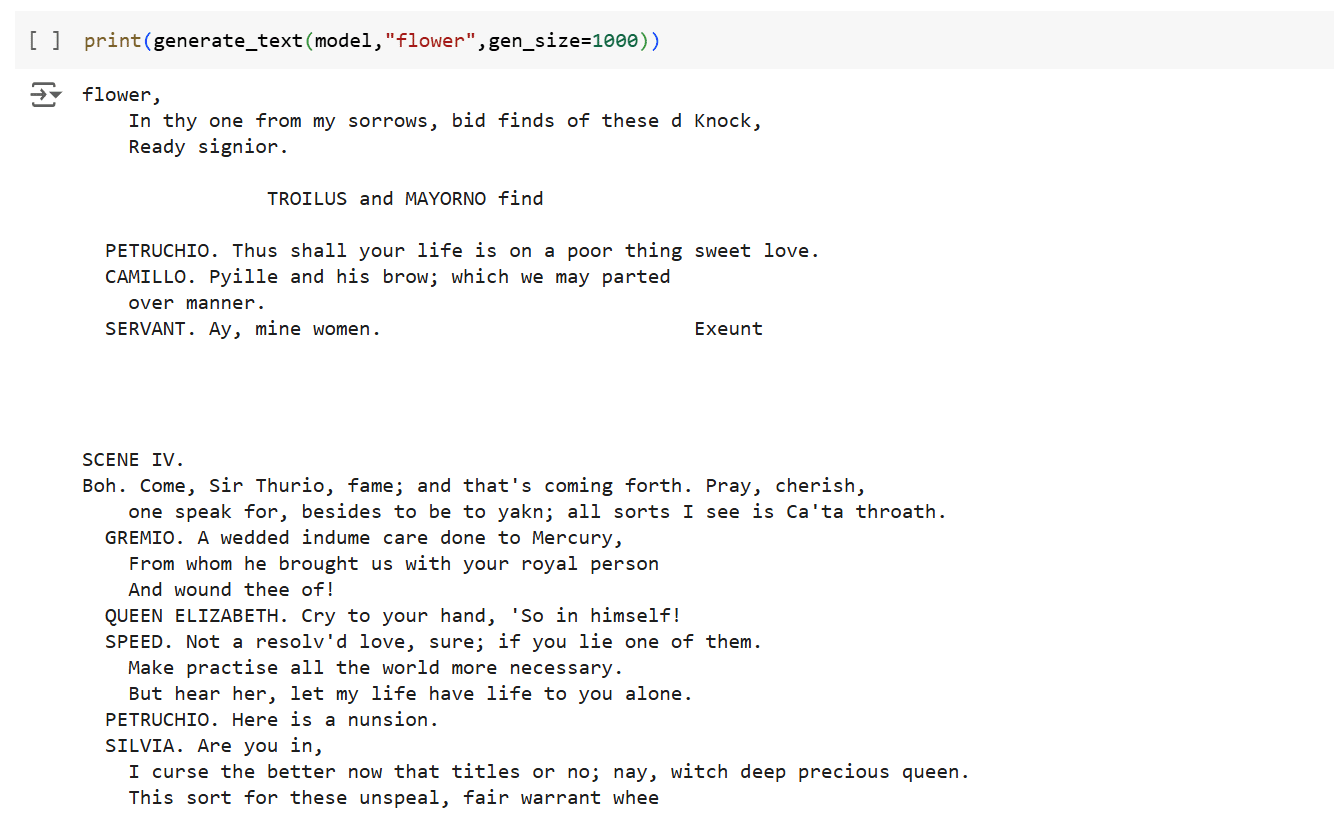
Nous avons créer un réseau de neurones qui génère de nouveaux textes à partir d’un corpus de données textuelles
But : Étant donné une séquence de chaîne d’entrée, prévoyez la séquence décalée d’un caractère vers l’avant.
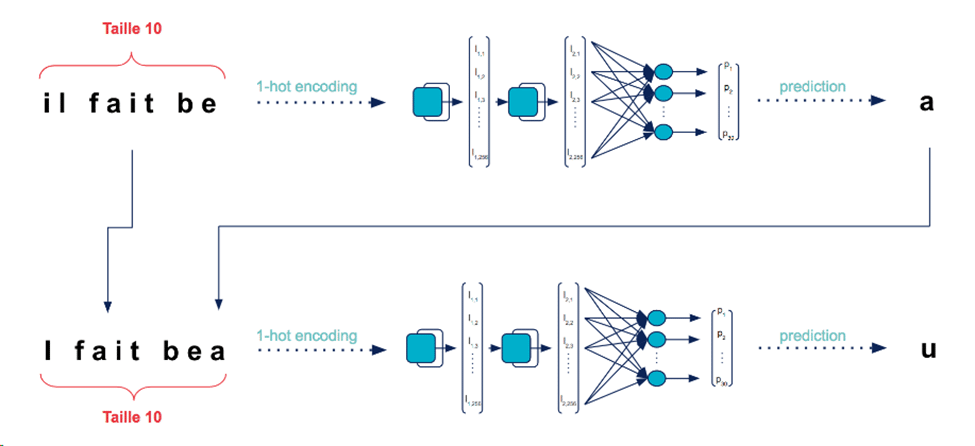
Dans notre exemple, nous utiliserons les œuvres de William Shakespeare en anglais.
Le RNN basé sur les caractères va en fait apprendre la structure de l’écriture des pièces et aussi l’espacement, juste au niveau du caractère !
On obtient après apprentissage un modèle capable de générer avec une assez bonne précision des texte similaires à celui de la pièce de Shakespeare.
Conclusion
Bien que les RNN, LSTM et GRU soient désormais accompagnés de modèles plus récents, ils restent essentiels pour comprendre les bases du NLP moderne. Leur capacité à apprendre les dépendances séquentielles a été une avancée décisive pour le traitement automatique du langage, inspirant et influençant profondément les technologies de pointe d’aujourd’hui.

L'interopérabilité des données - SmartData by Ntico
L'interopérabilité des données
Introduction
Les données sont devenues un élément essentiel pour la prise de décision des entreprises. La multiplication des sources et des formats de données dans un SI en constante évolution crée un défi majeur : l’interopérabilité.
Le potentiel de partage et de réutilisation des données de l’entreprise dépend de leur qualité, de leur découvrabilité et de leur gestion globale.
Afin de pouvoir pleinement dégager ce potentiel, chaque entreprise doit développer l’interopérabilité de ses données selon plusieurs axes que nous allons détailler.
Pourquoi a-t-on besoin de gérer l’interopérabilité des données ?
L’interopérabilité des données est la capacité de différents systèmes et applications à échanger et à utiliser des données de manière efficace, tant dans un contexte opérationnel que analytique.
Amélioration des prises de décision
Améliorer la prise de décision grâce aux données est devenu un enjeu fort pour les entreprises et accéder à une vue complète des données qu’ils ont à disposition doit leur permettre de prendre des décisions plus éclairées et plus rapides, en réduisant les silos d’information.
Stimulation de l'innovation
Cela aura également pour effet de stimuler l’innovation en permettant aux différents acteurs de l’entreprise d’accéder à de nouvelles sources de données et ainsi de développer de nouveaux produits et services.
Optimisation de l'intégration des données
Il est tout aussi important de diminuer les efforts de transformation et d’intégration des données pour gagner en qualité de données et en homogénéité du code source tout en facilitant l’automatisation des processus.
Collaboration et productivité
Enfin, améliorer la collaboration et la productivité des équipes en réduisant le cold start permettra de réduire le time to market mais aussi de réaliser des économies importantes sur le build des solutions.
Formes d’interopérabilité des données
Les formes d’interopérabilité des données sont multiples, chacune répondant à des besoins spécifiques.
Technique
Nous allons parler d’interopérabilité technique dès lors qu’il est question de la capacité des systèmes à échanger des données via des formats et des protocoles standardisés.
Sémantique
Il s’agit d’interopérabilité sémantique lorsque l’objectif consiste à permettre à des systèmes, mais également des utilisateurs, de comprendre la signification des données échangées ou consommées grâce à l’utilisation d’un vocabulaire commun.
Organisationnelle
Enfin, la mise en place de processus et de règles communes qui permettent à l’entreprise de collaborer et de partager des données de manière transparente et efficace fait référence à l’interopérabilité organisationnelle.
Comment garantir l’interopérabilité des données ?
La mise en place de l’interopérabilité des données est un processus complexe qui nécessite une approche holistique. L’entreprise doit donc se saisir de chacun des sujets qui seront abordés ci-dessous dans leur globalité, dans un planning maîtrisé, traitant en priorité les points les plus lacunaires, leur permettant de gagner rapidement et/ou facilement en efficacité opérationnelle.
Gouvernance des données
Définition de politiques de gouvernance des données
Il est bien sûr évident que la première chose à faire pour l’entreprise sera de définir des politiques de gouvernance des données pour garantir la qualité, la sécurité et l’accessibilité des données.
En définissant des standards de qualité pour les données, comme par exemple la non publication d’un jeu de données affichant une qualité non contrôlée ou inférieure à un seuil défini, il sera possible de maîtriser en sortie la qualité des indicateurs affichés. La qualité d’une donnée se mesure au travers des caractéristiques qui lui sont propres, pour lesquelles il est possible de mesurer l’exactitude, l’exhaustivité, la cohérence, la validité, la fraîcheur, l’intégrité ou encore la clarté. Il faudra pour cela mettre en place des processus pour garantir que les données sont conformes à ces standards, comme des moteurs de scoring ou encore des dashboards de monitoring.
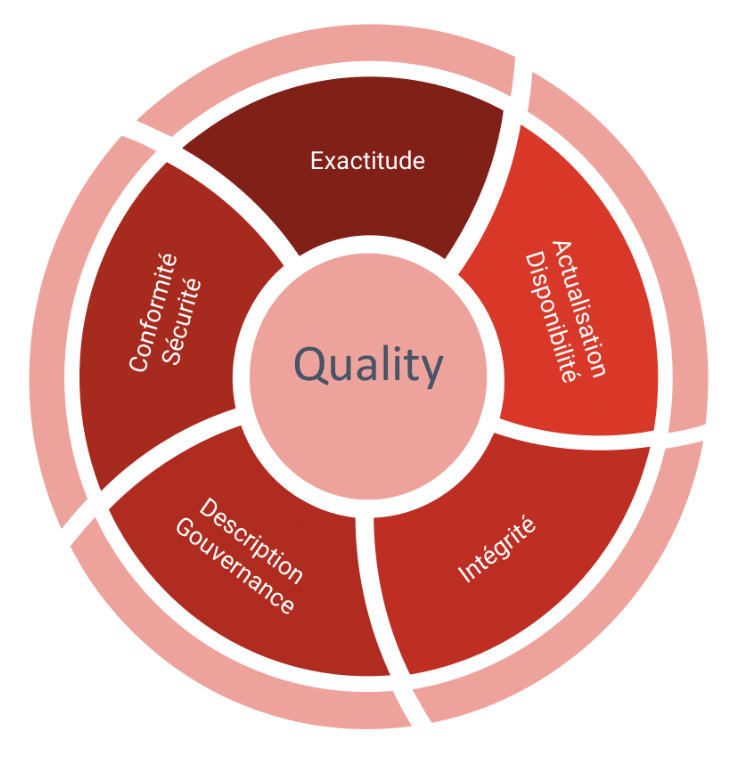
- Exactitude
Des données de bonne qualité commencent par être le reflet de la vérité. Et cela doit pouvoir se mesurer directement avec le système source. Il est alors possible de contrôler également la complétude des données.
- Actualisation / disponibilité
Mais une donnée exacte, si elle n’est pas actualisée régulièrement,risque de devenir obsolète et perdre toute utilité. Afin de pouvoir saisir toutes les opportunités, les données devront être disponibles au fur et à mesure de leur production , en cohérence avec les besoins des utilisateurs, allant du temps réel à J+1 généralement.
- Intégrité
Dans un objectif d’unicité des informations à l’échelle de l’entreprise, il convient de s’assurer qu’il n’y ait pas de doublons présents dans les données ni même dans les datasets exposés. Il est aussi important de garantir que les données de tous les systèmes de l’organisation soient bien synchronisées.
Couvrir un historique de données suffisant ainsi qu’une granularité fine pourra servir tous les besoins de calcul.
- Description / Gouvernance
La qualité descriptive des données réside dans leur facilité de localisation, leur interprétabilité et leur représentation cohérente. Afin de pouvoir garantir un accès facilité à la donnée, une entreprise doit être capable de retracer le lineage complet d’une donnée exposée, ceci jusqu’à sa source.
Des données décrites dans chaque couche de stockage seront facilement manipulées par les utilisateurs.
- Conformité / Sécurité
Enfin, les données, afin de servir au mieux la stratégie de l’entreprise, doivent respecter les normes et les règlements en vigueur dans l’espace où elles sont utilisées et être sécurisées de bout en bout en termes d’accès et de transport.
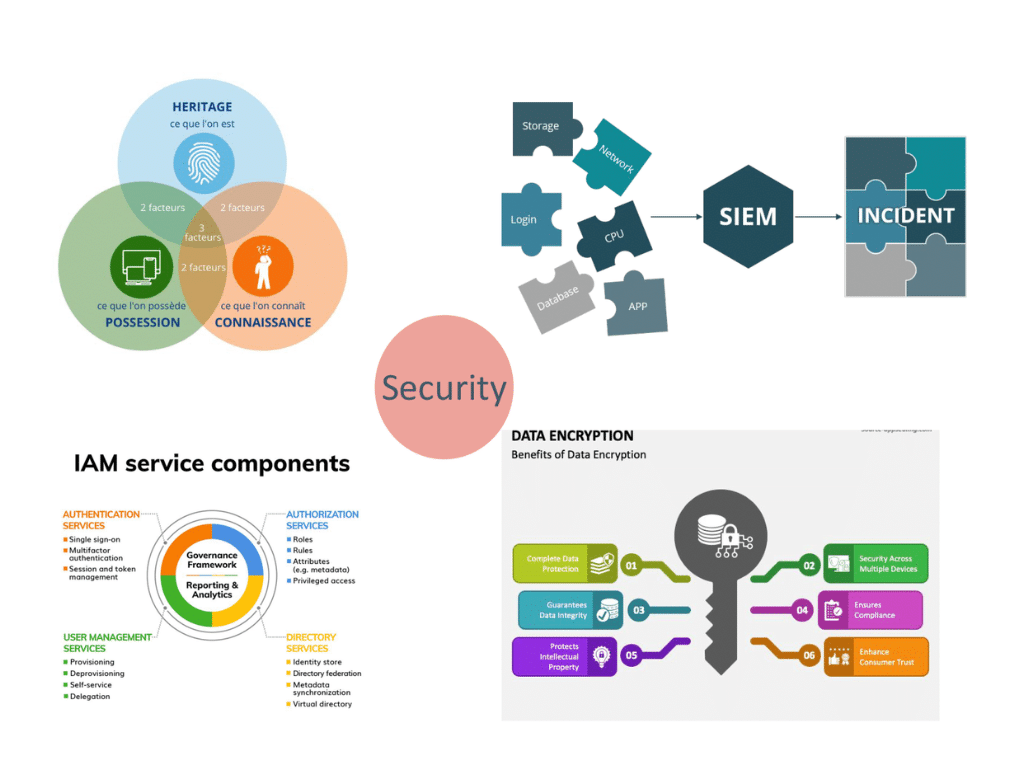
Mise en place de mesures de sécurité
La mise en place de mesures de sécurité pour protéger les données contre les accès non autorisés, la divulgation, la modification ou la destruction est essentielle. Ces mesures peuvent être techniques et contraignantes, elles peuvent également être organisationnelles et revues par du contrôle continu ou a posteriori. Il faudra outiller l’access management à minima puis dans un second temps la surveillance de ces accès au travers d’un SIEM (Security Information Event Manager).
Politique d'accès et outillage
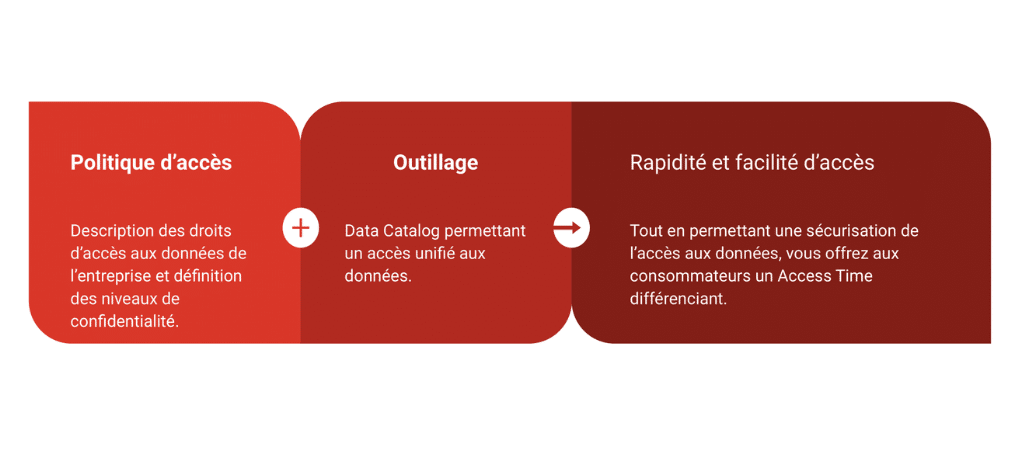
La mise à disposition d’une politique d’accès aux données et d’un outillage dédié permettra aux consommateurs de trouver et d’utiliser les données dont ils ont besoin avec facilité et rapidité. Celle-ci peut relever par exemple des niveaux de confidentialité ou encore de la gestion des autorisations délivrées automatiquement en fonction du contexte métier / utilisateur.
L’un des points importants qu’il faudra garder dans le viseur est la sensibilisation des parties prenantes à l’importance de la gouvernance des données et les former aux processus et aux outils mis en place.
Standardisation
Il est admis qu’adopter des formats et des protocoles standardisés pour l’échange de données en utilisant des formats et des protocoles communs est une bonne pratique afin que les différents systèmes et applications puissent échanger des données de manière efficace.
Format de données
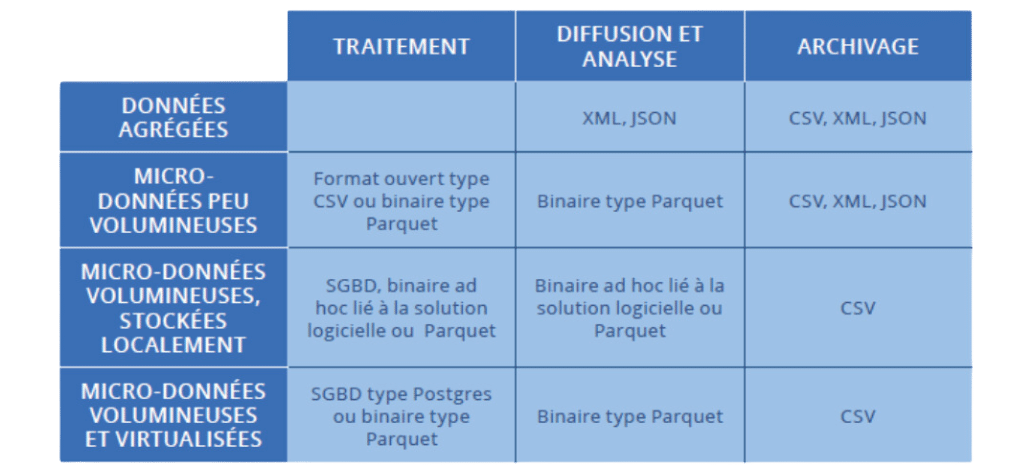
Il existe de nombreux formats de données différents, chacun ayant ses propres avantages et inconvénients. Quelques exemples de formats de fichiers les plus courants :
- CSV (Comma-Separated Values) : Format simple et largement utilisé pour stocker des données tabulaires.
- JSON (JavaScript Object Notation) : Format léger et facile à utiliser pour stocker des données structurées.
- Fichiers binaires : Formats spécifiques à une application pour stocker des données non structurées, comme des images ou des vidéos, ou structurées (Avro).
L’entreprise peut choisir de mettre en œuvre un seul ou plusieurs standards en fonction de son contexte technologique et des compétences des équipes.
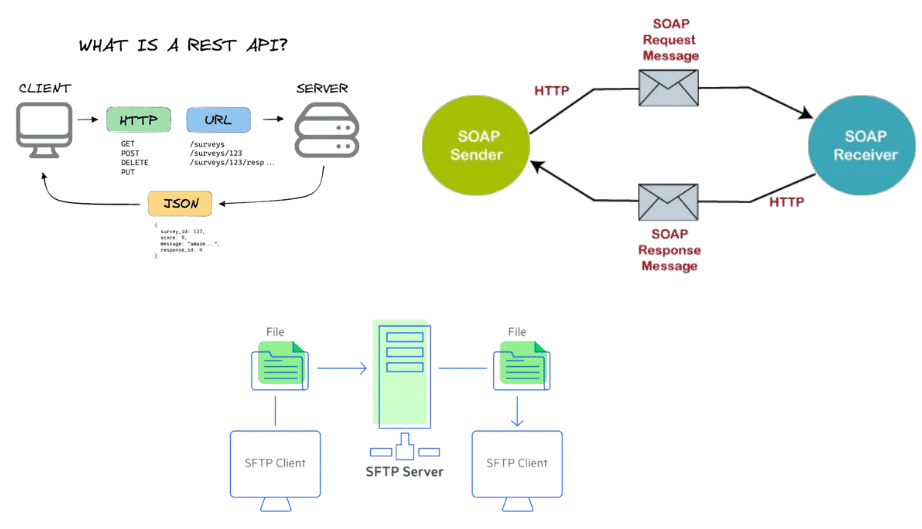
Protocoles de communication
Les protocoles de communication définissent les règles et les procédures pour l’échange de données entre deux systèmes. Parmi les protocoles les plus courants en matière d’échange de données, on peut citer :
- FTP (File Transfer Protocol): Protocole utilisé pour le transfert de fichiers.
- SOAP (Simple Object Access Protocol): Protocole utilisé pour l’échange de messages XML entre des applications Web.
- REST (Representational State Transfer): Architecture logicielle pour les services Web.
Les entreprises seront souvent amenées à mettre en œuvre plusieurs protocoles de communication afin de pouvoir traiter leurs échanges de données avec la temporalité nécessaire à chaque cas d’usage (Batch vs Real Time).
Couche sémantique
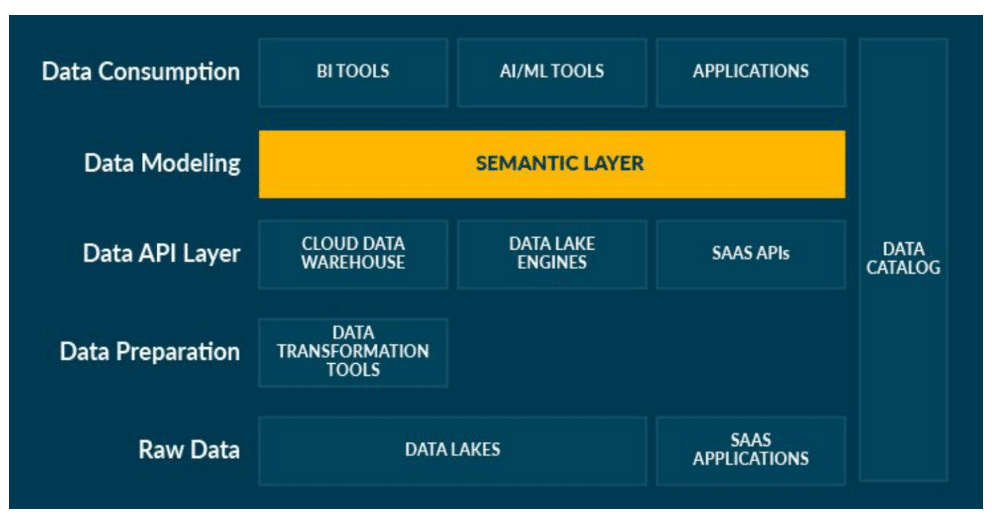
La mise en place d’une couche sémantique dans l’exposition des données aux consommateurs doit permettre l’utilisation d’un vocabulaire commun dont le rôle sera de faire le pont entre la terminologie informatique, parfois contrainte par les systèmes sources, et les expressions métier de cette même donnée, en agissant comme une table de traduction.
L’utilisation de schémas décrivant les liens entre les données aidera également à la compréhension des données exposées. Le tout permettra d’associer facilement une signification aux données et de les positionner dans un domaine de connaissances.
Le second avantage à utiliser une couche sémantique réside dans la faculté d’exposer un modèle de données commun empêchant la survenue de problèmes d’écarts de données dû à l’utilisation de différentes sources de données.
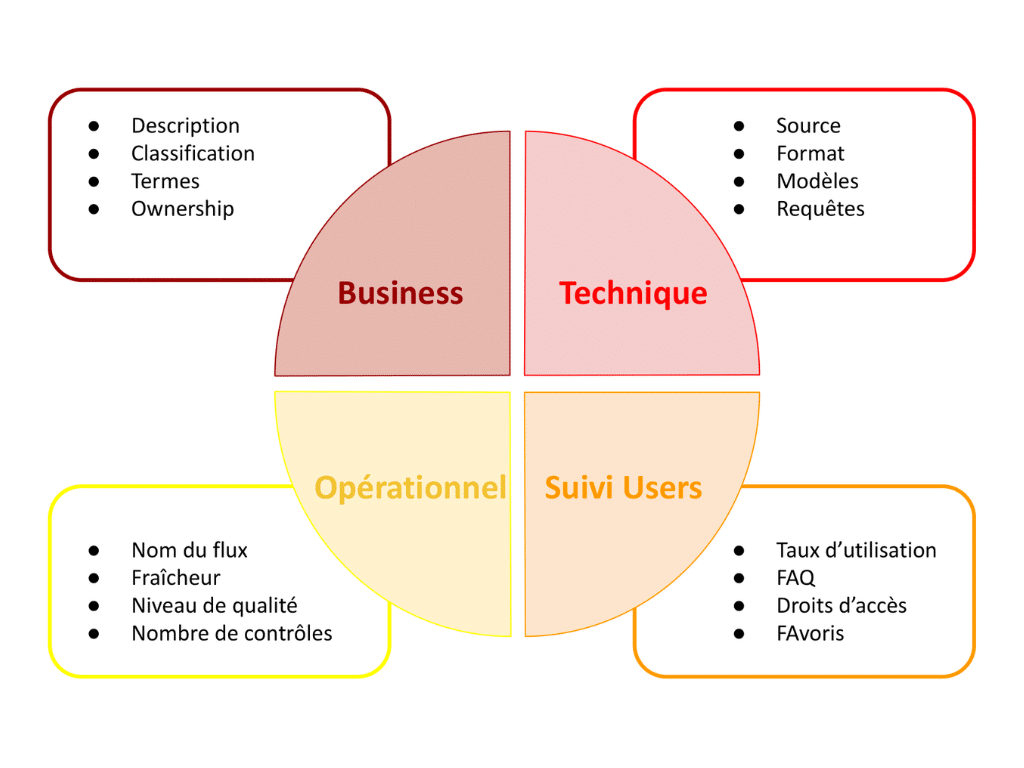
Métadonnées
Les métadonnées servent à enrichir les données pour en faciliter la compréhension et l’utilisation. Il s’agit pour cela d’ajouter des informations, généralement sous forme de tags ou de labels, pour les décrire et les contextualiser. Il est possible d’ajouter des natures d’information très diverses dont les types seront le plus généralement : Business, Technique, Opérationnel, Suivi Utilisateur. – cf schéma.
Cela aura également pour effet d’améliorer la recherche et la découverte des données mais aussi a fortiori leur utilisation dans l’analyse et pour la prise de décision.
Il conviendra d’alimenter le plus possible les métadonnées automatiquement dès lors que les outils le permettent, mais il sera nécessaire d’investir du temps dans l’ajout manuel de ces dernières par les Technical Owners et Business Owners, car sans cet effort de documentation, le pari de la démocratisation des données est perdu d’avance.
Outils et technologies
La garantie d’une interopérabilité des données complète et efficace passe par la mise en place d’un socle technologique commun, partagé et mutualisé. Il sera constitué de différents outils permettant d’adresser les objectifs cités précédemment, mis à disposition sous formes de produits self-service facilitant les usages :
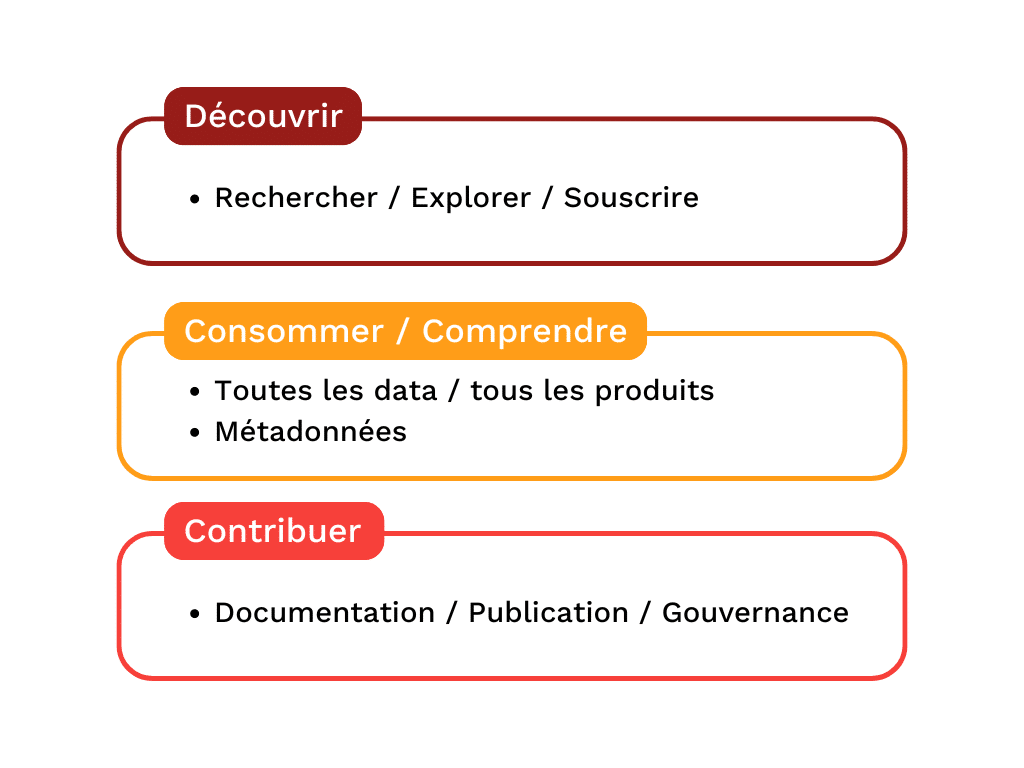
Le Catalogue de données
L’un des besoins à adresser prioritairement sera sans doute le Catalogue de données unique, permettant à toutes les parties prenantes de se retrouver en un point central.
D’une part les producteurs de données pour référencer, documenter et gouverner les données, d’autre part les consommateurs de données pour explorer, rechercher, et souscrire à l’utilisation des données. Il devra permettre de gérer tous les types de métadonnées définis comme étant mandatory par la gouvernance.
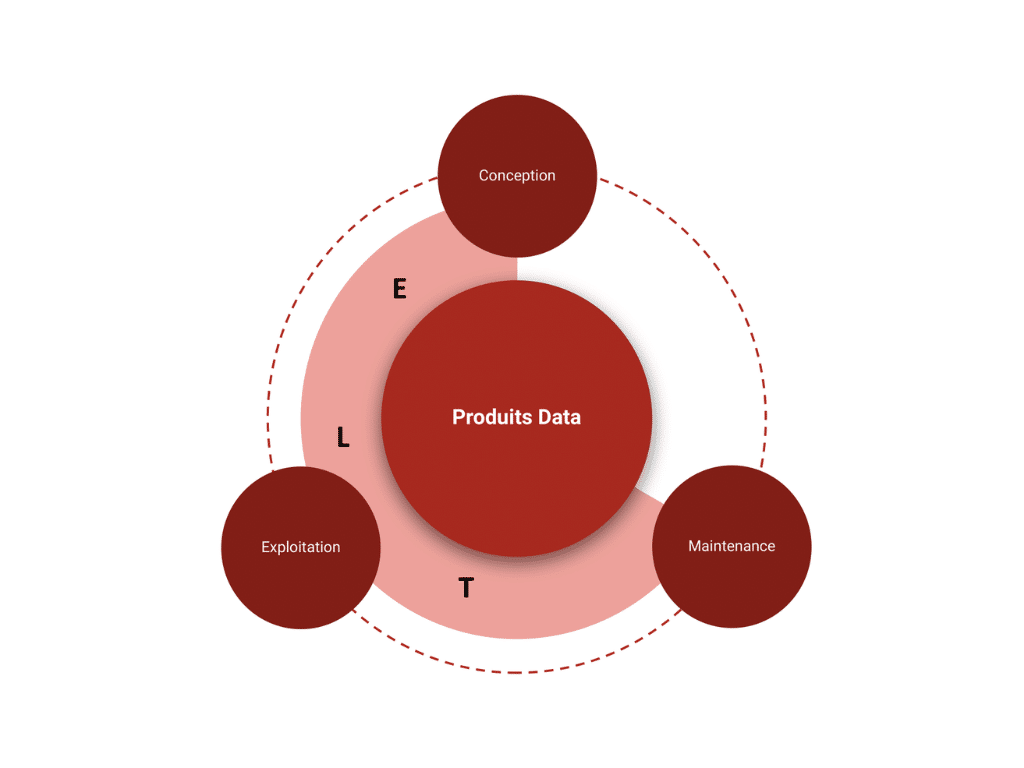
Pipeline de données
En second lieu, l’utilisation d’un outil de pipeline de données commun apportera des bénéfices substantiels dans la mise en oeuvre réussie de l’interopérabilité de vos données.
Un ELT/ETL mutualisé permettra de simplifier les échanges de données et alignera tous les utilisateurs sur des protocoles et moyens de déclenchements unifiés.
Cette mutualisation vise à permettre aux différents domaines de l’entreprise de provisionner des ressources techniques à la demande pour la conception et l’exploitation de leurs produits de données, ceci de façon simple et homogène, de sorte à faciliter la maintenance de tous les produits.
Nous adressons un double objectif grâce à cette logique en rationalisant le socle et les technologies utilisées à travers l’entreprise.
Deux éléments essentiels sont à prendre en compte lorsque vous pensez votre architecture autour de ce socle commun :
- Évaluer votre environnement technologique en tenant compte des systèmes et applications existants mais aussi et surtout des compétences internes et des budgets disponibles à court, moyen et long terme.
- Choisir une solution évolutive en privilégiant des solutions capables de s’adapter à l’évolution de vos besoins, le moins vendorlocked possible voire cloud provider agnostique.
Culture du partage
Dernier aspect favorisant l’interopérabilité (des données) en entreprise, mais pas des moindres.
L’encouragement d’une culture du partage et de la collaboration entre les différents services de l’entreprise au travers de l’innersourcing, mais aussi de la mise en place de communautés transverses, permettra de stimuler l’innovation au sein des équipes.
Conclusion
Nous pouvons constater, à la lecture de cet article, que les entreprises sont face à un vaste chantier lorsqu’il s’agit de l’interopérabilité des données.
Les parties prenantes sont nombreuses et leurs souhaits sont parfois compliqués à réconcilier au sein d’une même politique. C’est un véritable enjeu d’adoption qu’il faut gérer via un plan d’acculturation adapté favorisant ainsi la fédération des différentes équipes sur la ligne de conduite à adopter.
Ces efforts de convergence des pratiques ont alors un effet bénéfique visant à simplifier la collaboration et les développements ce qui conduira à démocratiser l’usage des données.
Dans le même temps, des économies d’échelle pourront être constatées sur le build mais aussi le run des solutions mises en œuvre dans le respect de la politique commune.
Deux éléments essentiels seront toujours à prendre en compte lorsque vous penserez à votre architecture autour de ce socle commun :
- Évaluer votre environnement technologique en tenant compte des systèmes et applications existants mais aussi et surtout des compétences internes et des budgets disponibles à court, moyen et long terme.
- Choisir des solutions capables de s’adapter à l’évolution de vos besoins, le moins vendorlocked possible voire cloud provider agnostique.

Événement Data Lille - Smart Data

SMART DATA
Événement Smart Data x Data Lille !
En septembre s’est déroulé le Meetup Data Lille sponsorisé par Ntico ! 🙌
À cette occasion, nous avons invité Kestra à venir présenter sa Plateforme de Data Orchestration, sur laquelle nous avons ensuite effectué un retour d’expérience relatant nos usages dans le cadre du développement de la solution LoCXia 🚀
S’en est suivi un moment convivial qui a permis de continuer la discussion autour de nombreux sujets centrés sur le domaine de la Data ! 🤗

Événement Data - SmartData by Ntico
Événement Data
La communauté SmartData organise un événement !
C’est la rentrée pour la communauté SmartData by Ntico !
Et pour bien commencer le mois de septembre, on vous propose un événement, en partenariat avec Data Lille ! 🚀
Au programme : découvrez l’outil Kestra et notre retour d’expérience sur son utilisation lors du développement de LoCXia, plateforme de données géospatiales sur-mesure !
📅 26 septembre 2024 – 🕐 18h30
📍 Euratechnologies – 5ème étage (on espère que vous aimez les vues imprenables) – 🦽 Accessible
Pour vous inscrire, ça se passe ici : https://lnkd.in/eMY8VWYB